
As many of you know, hugepages are essential for optimizing memory usage in high-performance applications like databases and scientific computing. They allow for larger memory blocks, reducing overhead and minimizing Translation Lookaside Buffer (TLB) misses. However, proper alignment when mapping huge pages is crucial to ensure smooth operation.
🔗 Patch notes and related discussions here: Linux Kernel Bugzilla Report https://lnkd.in/gz4zmJHe
🔗 Code changes – https://lnkd.in/guBtu6fF
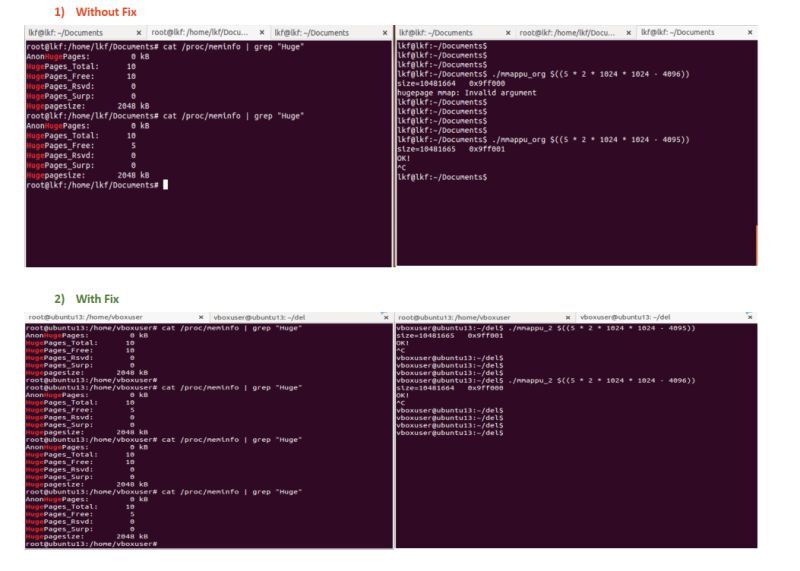
For this reproduction, We 𝐮𝐭𝐢𝐥𝐢𝐳𝐞𝐝 𝐎𝐫𝐚𝐜𝐥𝐞 𝐕𝐌 𝐰𝐢𝐭𝐡 𝐔𝐛𝐮𝐧𝐭𝐮13.04 𝐛𝐢𝐧𝐚𝐫𝐢𝐞𝐬, 𝐬𝐩𝐞𝐜𝐢𝐟𝐢𝐜𝐚𝐥𝐥𝐲 𝐤𝐞𝐫𝐧𝐞𝐥 𝐯𝐞𝐫𝐬𝐢𝐨𝐧 3.8.0-19-𝐠𝐞𝐧𝐞𝐫𝐢𝐜.
Although this issue is quite old, it’s beneficial to reproduce it and apply the proposed fix to deepen our understanding of hugepage-related code changes and their workings.
This discussion is particularly valuable for novice kernel developers or engineers aspiring to build their careers in kernel and device driver development.
A regression introduced in commit 40716e2 led to the kernel returning -EINVAL (invalid argument) unless the requested memory mapping length was “almost” aligned to a huge page boundary. This issue stemmed from moving alignment checks into hugetlb_file_setup() without adjusting the caller-side logic, leading to misalignment errors.
To address this, a patch partially reverts the previous changes and introduces necessary alignment logic back at the caller level. Key modifications include:
1) 𝐡𝐮𝐠𝐞𝐭𝐥𝐛_𝐟𝐢𝐥𝐞_𝐬𝐞𝐭𝐮𝐩() 𝐟𝐮𝐧𝐜𝐭𝐢𝐨𝐧:
Now takes an additional ‘addr’ parameter.
Aligns the size to hugepage boundaries within the function.
2) 𝐂𝐚𝐥𝐥𝐞𝐫-𝐬𝐢𝐝𝐞 𝐜𝐡𝐚𝐧𝐠𝐞𝐬:
mmap_pgoff() and newseg() now pass the address to hugetlb_file_setup().
Removes redundant alignment checks in these callers.
3) 𝐀𝐥𝐢𝐠𝐧𝐦𝐞𝐧𝐭 𝐜𝐚𝐥𝐜𝐮𝐥𝐚𝐭𝐢𝐨𝐧:
Uses ALIGN macro to ensure proper hugepage alignment.
Calculates the number of pages based on the aligned size.
4) 𝐈𝐦𝐩𝐚𝐜𝐭 𝐨𝐧 𝐬𝐡𝐦𝐠𝐞𝐭():
Previously, shmget() with SHM_HUGETLB flag only aligned to PAGE_SIZE.
Now, it aligns to the actual hugepage size.
5) 𝐅𝐢𝐥𝐞 𝐜𝐡𝐚𝐧𝐠𝐞𝐬:
mm/hugetlb.c: Main changes to hugetlb_file_setup().
include/linux/hugetlb.h: Updated function prototype.
ipc/shm.c: Modified newseg() to use the new hugetlb_file_setup().
mm/mmap.c: Updated mmap_pgoff to use the new function signature.
These enhancements not only resolve existing issues but also bolster the robustness of the kernel’s memory management for applications that depend on hugepages.
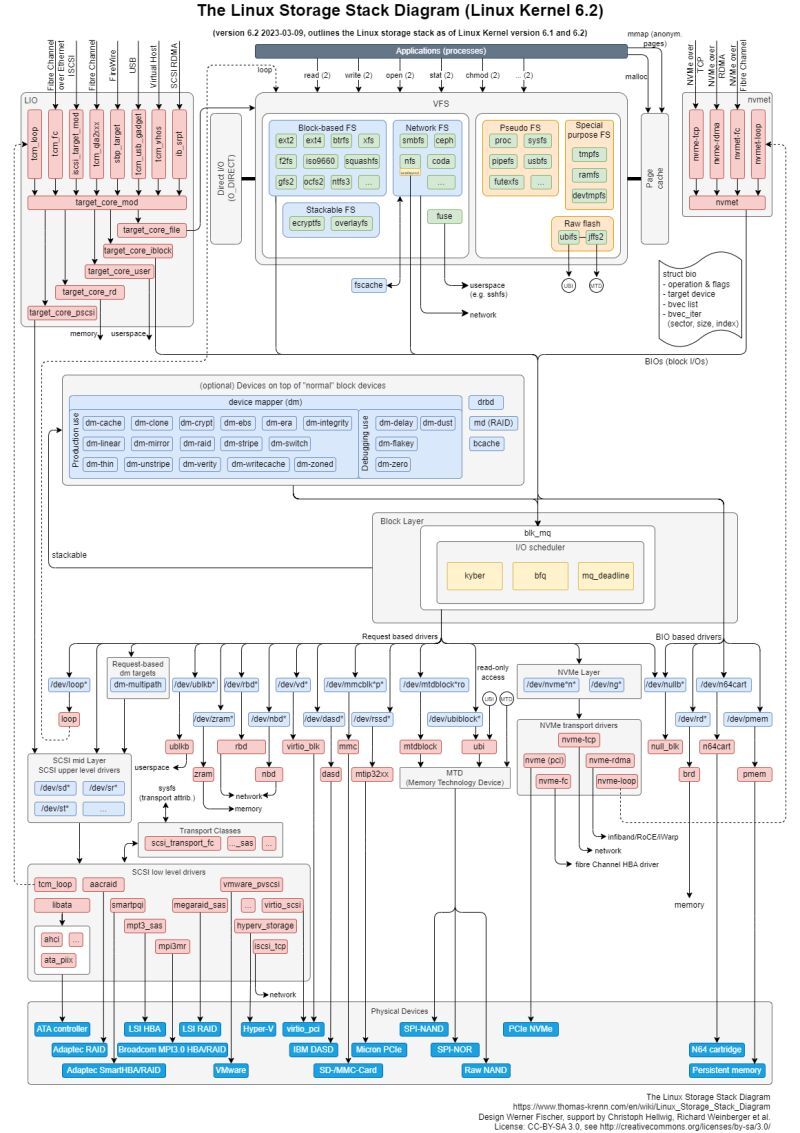
Are you ready to dive into the world of block device drivers? Let’s explore how these crucial components power our storage systems!
📽 YouTube link -> https://lnkd.in/gwae9g_F
Block device drivers, manage data in fixed-size chunks or blocks. These blocks ensure efficient reading and writing operations, making them ideal for storage devices.
Most block devices are associated with storage systems, though they aren’t limited to this use. They ensure that data is read and written in fixed blocks, a critical feature for maintaining data integrity and performance in storage systems.
VFS: Acts as an interface to the file system, providing a standard interface for different file systems to communicate with the kernel.
File System Interaction: Block drivers work closely with the file system. When an application needs to read or write data, it first interacts with the
Virtual File System (VFS), which then communicates with the file system. The file system, in turn, interacts with the block layer, which accesses the physical storage devices.
Page Cache: Data often goes through the page cache before reaching the file system, ensuring faster access and efficient data management.
Direct I/O (O_DIRECT): This mode allows bypassing the page cache, enabling direct read/write operations between the application and storage, crucial for specific high-performance applications.
Scheduling: Just like process scheduling, block drivers have their own schedulers to manage I/O requests. This is crucial for optimizing performance and meeting deadlines.
🔵 Blk_mq (Block Multi-Queue): A framework that improves scalability and performance by allowing multiple hardware and software queues.
IO Schedulers
📊 Block Size in Linux:
In Linux, the typical block size is 4KB, though hardware may use different sizes, commonly 512 bytes in modern systems.
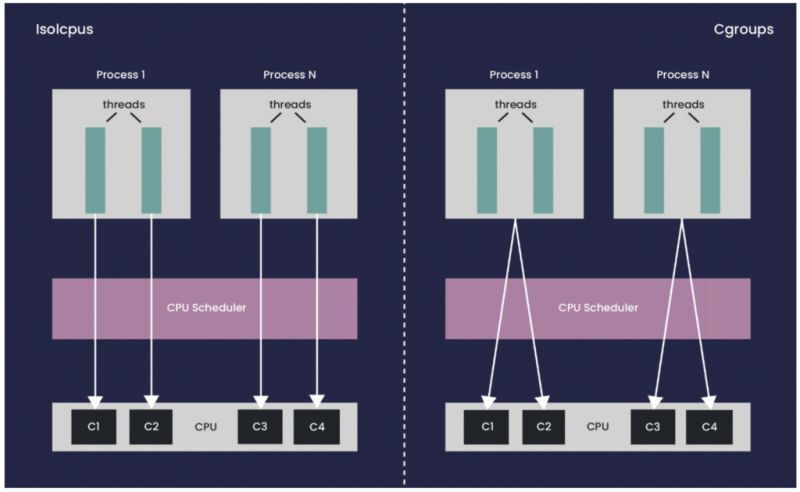
CPU Isolation is a Linux kernel feature that designates specific CPUs as isolated from general-purpose scheduling. Isolated CPUs do not handle regular workloads; instead, they focus on specialized tasks like real-time processing. This reduces interruptions and leads to lower latencies and more predictable performance.
The nohz_full feature allows certain CPUs to enter a “no-tick” mode, where they don’t receive timer interrupts. This is beneficial for low-latency scenarios, such as real-time applications, by reducing timer interrupt overhead and improving performance.
In a standard system, the kernel sends timer interrupts to all CPUs for scheduling. These can cause context switches and overhead.
With nohz_full enabled, CPUs in no-tick mode only receive timer interrupts when absolutely necessary, allowing tasks to execute uninterrupted.
The nohz_full feature addresses the needs of real-time and high-performance applications that require predictable latencies.
𝐑𝐞𝐝𝐮𝐜𝐞 𝐋𝐚𝐭𝐞𝐧𝐜𝐲: Eliminating timer interrupts significantly lowers task latency.
𝐈𝐦𝐩𝐫𝐨𝐯𝐞 𝐏𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞: Applications like multimedia processing and gaming benefit from reduced overhead.
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐑𝐞𝐚𝐥-𝐓𝐢𝐦𝐞 𝐀𝐩𝐩𝐥𝐢𝐜𝐚𝐭𝐢𝐨𝐧𝐬: It configures CPUs for real-time workloads.
When utilizing nohz_full, it is crucial to manage CPU isolation settings correctly:
𝐁𝐨𝐨𝐭 𝐂𝐏𝐔: The boot CPU (the CPU that initializes the kernel and starts the system) must not be included in the nohz_full mask. This is essential because the boot CPU handles critical tasks during the boot process, including initializing other CPUs and managing timers.
𝐇𝐨𝐮𝐬𝐞𝐤𝐞𝐞𝐩𝐢𝐧𝐠 𝐂𝐏𝐔𝐬: Are responsible for executing system tasks, such as timer management and scheduling. If the boot CPU is incorrectly isolated, it can lead to issues, such as kernel crashes during the boot process.
A regression in the Linux kernel caused crashes when the boot CPU was included in the nohz_full mask.
𝐓𝐡𝐞 𝐫𝐞𝐜𝐞𝐧𝐭 𝐩𝐚𝐭𝐜𝐡:
𝐑𝐞𝐬𝐭𝐨𝐫𝐞𝐬 𝐂𝐡𝐞𝐜𝐤𝐬: Prevents the boot CPU from being included in the nohz_full mask for stability.
𝐔𝐩𝐝𝐚𝐭𝐞𝐬 𝐇𝐚𝐧𝐝𝐥𝐢𝐧𝐠 𝐨𝐟 𝐈𝐬𝐨𝐥𝐚𝐭𝐞𝐝 𝐂𝐏𝐔𝐬: Ensures the kernel can determine available CPUs without causing crashes.
𝐑𝐞𝐥𝐚𝐭𝐞𝐝 𝐋𝐢𝐧𝐤𝐬 𝐚𝐧𝐝 𝐅𝐮𝐫𝐭𝐡𝐞𝐫 𝐑𝐞𝐚𝐝𝐢𝐧𝐠📚
https://lnkd.in/gFAd6ypP
As technology continues to advance, the Linux kernel plays a critical role in powering our devices and systems. Ensuring its reliability is paramount, especially in today’s multi-core and multi-threaded computing environments. That’s where the Kernel Concurrency Sanitizer (KCSAN) comes into play.
The development of KCSAN was spurred by the need to address a common yet challenging problem in kernel development – concurrency-related bugs and data races. These bugs occur when multiple threads or CPUs concurrently access shared data without proper synchronization, leading to unpredictable and potentially incorrect behavior. Identifying and mitigating such issues is crucial for maintaining the stability and security of the Linux kernel.
KCSAN is a powerful tool designed to detect and mitigate concurrency-related issues in the Linux kernel. Here’s how it does it:
KCSAN is a testament to the commitment of the open-source community to enhance the robustness and reliability of the Linux kernel. It empowers developers to tackle complex concurrency issues head-on, making the kernel more resilient and less prone to crashes or incorrect behavior in today’s demanding computing environments.
👏 Kudos to the developers and contributors behind KCSAN for their dedication to improving the core of open-source technology! Let’s continue to support and invest in tools like KCSAN to ensure that the Linux kernel remains a rock-solid foundation for innovation.
Gratitude to LPC team for spotlighting Data-Race Detection in the Linux Kernel! Sharing the insightful presentation covered by LPC
📺 YouTube session recording: https://lnkd.in/gFJQAVj9 👀📹
PCIe (Peripheral Component Interconnect Express) drivers are software components that facilitate communication between the operating system and PCIe devices connected to a computer’s motherboard. These drivers enable the efficient transfer of data between the CPU and PCIe devices, ensuring seamless functionality.
PCIe drivers play a crucial role in maximizing the performance of PCIe devices such as network cards, graphics cards, SSDs, and more. By providing a standardized interface for communication, these drivers enable high-speed data transfer, low latency, and optimal resource utilization, enhancing overall system efficiency.
PCIe drivers are essential whenever PCIe devices are integrated into a computer system. Whether you’re building a gaming rig, configuring a server, or developing embedded systems, PCIe drivers are necessary to ensure proper device recognition, configuration, and operation.
PCIe configuration space refers to a set of registers within PCIe devices that contain crucial information about device capabilities, status, and control settings. PCIe drivers interact with this configuration space to initialize devices, allocate resources, and manage device operations effectively.
PCIe drivers are indispensable components in modern computing, enabling seamless communication and optimal performance for PCIe devices. Understanding their role and importance is key to harnessing the full potential of PCIe technology.
+++++++++++++++++++++++++++++++++++++++++++++++++
In this video, you’ll learn step-by-step how to access PCIe configuration space using a Linux kernel module. From understanding PCIe basics to implementing code to interact with PCIe configuration registers, this tutorial provides a hands-on approach to exploring PCIe functionality within the Linux environment.
https://lnkd.in/gy_bE3vg
Whether you’re a beginner looking to understand PCIe or an experienced developer seeking to enhance your skills, this tutorial is for you. Start your journey into PCIe configuration with Linux today!
Live patching is an essential feature in Linux systems, enabling the application of updates and security patches to a running kernel without requiring a reboot. This ensures uninterrupted system uptime, crucial for high-availability environments.
📽 Session Link – https://lnkd.in/gMj2Z3uD
Live patching involves applying updates to a running Linux kernel without stopping it. This is critical for maintaining system security and performance.
🔗 Register the Kernel Live Patch Module:
Before applying patches, register the live patch module with the kernel to prepare the system for changes.
🛠️ Enable the Live Patching Feature:
Activate the patch by enabling live patching. This redirects execution to the updated functions instead of the original ones.
❌ Disable and Unregister Patching:
You can disable live patching to revert to the original functions. To remove the patch, unregister it to clean up the system.
When a patch is applied, it is registered but not immediately active. The registration sets up the environment for the patch. The patch becomes active once enabled, rerouting calls to the new functions.
For instance, registering a patch makes it visible in /sys/kernel/livepatch/.
The kernel continues using the old functions until the patch is enabled. Enabling the patch redirects the system to the new functionality.
Live patching uses technical steps to switch between old and new functions seamlessly:
⛔ NOP Instruction: The kernel uses a ‘NOP’ (No Operation) instruction before critical functions, allowing changes to be introduced without immediate effect.
🔀 Function Redirection: Upon enabling live patching, the system replaces the NOP with a jump to the new function, bypassing the old code.
Disabling the patch reverts the kernel to its original state, executing the old functions. You can also remove the patch if it’s no longer needed.
🕒 Zero Downtime: Eliminates the need for system downtime, crucial for continuously available systems.
🔒 Immediate Security Updates: Allows immediate application of security patches, ensuring prompt vulnerability resolution.
📈 Increased Kernel Size: The kernel may become larger, leading to slight performance overhead.
🔍 Traceable Functions Required: Live patching relies on functions marked for tracing. Unmarked functions can’t be patched, limiting live patching’s scope.
🌐 KernelCare: Provides automatic live patching across multiple Linux distributions.
🖥️ kGraft: Developed by SUSE for live patching.
🔧 kpatch: Used by Red Hat for live kernel patching.
☁️ Ksplice: Supports live patching on Oracle Linux.
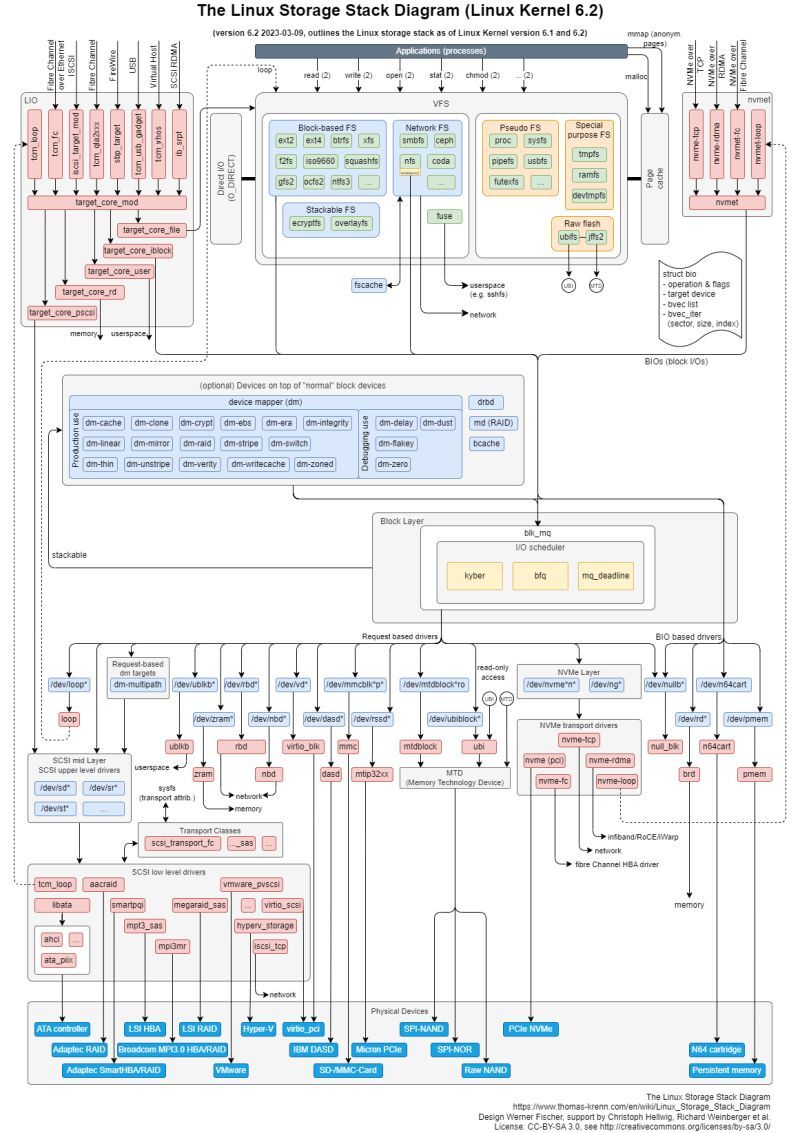
Are you ready to dive into the world of block device drivers? Let’s explore how these crucial components power our storage systems!
📽 YouTube link -> https://lnkd.in/gwae9g_F
Block device drivers, manage data in fixed-size chunks or blocks. These blocks ensure efficient reading and writing operations, making them ideal for storage devices.
Most block devices are associated with storage systems, though they aren’t limited to this use. They ensure that data is read and written in fixed blocks, a critical feature for maintaining data integrity and performance in storage systems.
VFS: Acts as an interface to the file system, providing a standard interface for different file systems to communicate with the kernel.
File System Interaction: Block drivers work closely with the file system. When an application needs to read or write data, it first interacts with the
Virtual File System (VFS), which then communicates with the file system. The file system, in turn, interacts with the block layer, which accesses the physical storage devices.
Page Cache: Data often goes through the page cache before reaching the file system, ensuring faster access and efficient data management.
Direct I/O (O_DIRECT): This mode allows bypassing the page cache, enabling direct read/write operations between the application and storage, crucial for specific high-performance applications.
Scheduling: Just like process scheduling, block drivers have their own schedulers to manage I/O requests. This is crucial for optimizing performance and meeting deadlines.
🔵 Blk_mq (Block Multi-Queue): A framework that improves scalability and performance by allowing multiple hardware and software queues.
IO Schedulers:
◾ Kyber: Designed for solid-state drives (SSDs), it aims to provide low latency and high throughput.
◾ BFQ (Budget Fair Queueing): Focuses on providing fairness and responsiveness, making it suitable for desktops and interactive applications.
◾ MQ Deadline: Ensures that I/O requests are serviced within a set deadline, balancing performance and latency.
📊 Block Size in Linux:
In Linux, the typical block size is 4KB, though hardware may use different sizes, commonly 512 bytes in modern systems.
gcov is a tool used to measure code coverage and generate profiling information for C code. It helps developers understand which parts of their code are actually being executed during program runs.
⚫ Measures the percentage of lines, statements, or functions in your code that are executed at least once during a test run. 📊
⚫ Helps identify areas of code that might not be adequately tested and could potentially contain bugs. 🐞
⚫ Useful for focusing testing efforts on areas with low coverage. 🔍
⚫ Provides information about how often different parts of your code are executed. ⏱️
⚫ Helps identify performance bottlenecks by pinpointing code that is executed frequently. 🚦
⚫ Allows for optimization efforts to be directed towards the most impactful areas. 💡
In this video, you’ll learn how gcov tracks code coverage during program runs, providing detailed analysis on line and function coverage. It ensures test cases cover all program parts, crucial for preventing production issues. Linux kernel developers use similar tools like Kcov. Enabling coverage during unit testing ensures thorough code path testing and identifies untested areas for improvement.
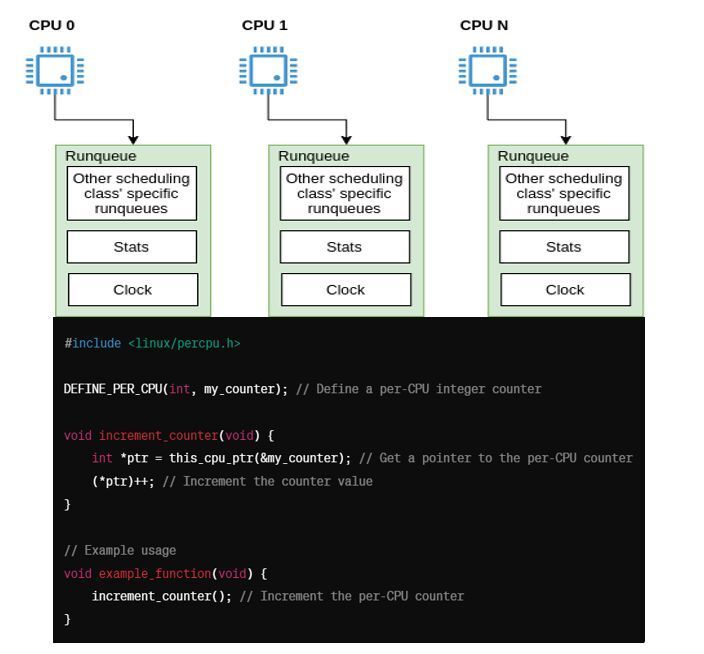
Cache line bouncing, a common challenge in multi-core systems, can lead to significant performance overheads. But fear not! Per-CPU data structures come to the rescue, offering a solution to this problem.
When multiple processors access the same memory location concurrently, they may each have their own cached copy of the data. If one processor modifies its cached copy, it needs to notify other processors to invalidate or update their copies to maintain data coherence across the system. This process, known as cache coherence, can result in cache line bouncing, where cache lines are repeatedly invalidated and updated across different CPU caches, leading to increased latency and reduced performance.
Per-CPU data structures address this issue by providing each processor with its own instance of the data structure, effectively eliminating the need for cache coherence protocols to synchronize shared data across multiple cores. Instead of accessing a single shared data structure, each CPU accesses its own private copy, reducing cache line bouncing and improving overall system performance.
In the Linux kernel, cache coherence is managed through mechanisms like cache invalidation, cache flushing, and memory barriers. One example of how cache coherence is maintained in the Linux kernel is through the use of cache maintenance functions like flush_cache_range() and invalidate_dcache_range().
Sample code example from the Linux kernel to illustrate how per-CPU data structures are implemented:
hashtag#include <linux/percpu.h>
DEFINE_PER_CPU(int, my_counter); // Define a per-CPU integer counter
void increment_counter(void) {
int *ptr = this_cpu_ptr(&my_counter); // Get a pointer to the per-CPU counter
(*ptr)++; // Increment the counter value
}
// Example usage
void example_function(void) {
increment_counter(); // Increment the per-CPU counter
}
In this example, we define a per-CPU integer counter using the DEFINE_PER_CPU macro provided by the Linux kernel. Each CPU core will have its own instance of this counter, stored in its private memory space. When increment_counter() is called, it increments the value of the counter associated with the current CPU core, avoiding cache line bouncing and improving performance.
By leveraging per-CPU data structures, developers can design more efficient and scalable multi-core systems, achieving better performance and reduced overhead in shared-memory architectures.
So, the next time you encounter cache line bouncing in your multi-core application, consider using per-CPU data structures to optimize performance and enhance scalability.
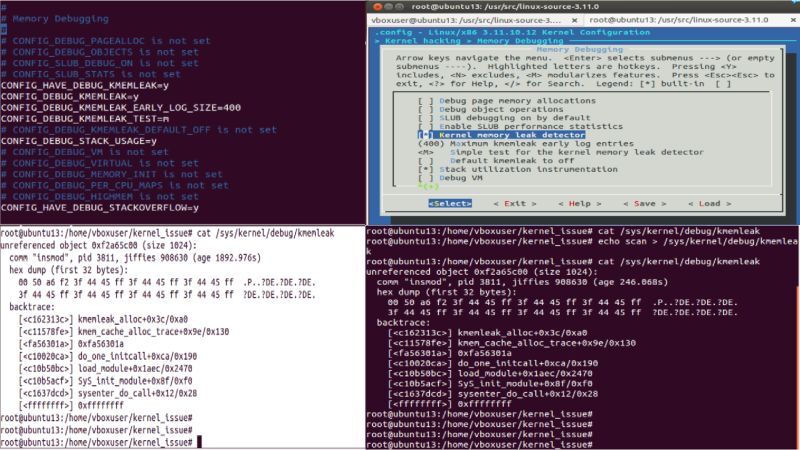
𝐤𝐦𝐞𝐦𝐥𝐞𝐚𝐤 is a powerful memory debugging tool within the Linux kernel, designed to detect memory leaks by tracking kernel memory allocations and identifying memory that has been allocated but not freed.
✔ Enabling `kmemleak` in the Kernel
Step 1: Kernel Configuration
1. Navigate to the Kernel Source Directory:
cd /usr/src/linux-source-x.x.x
2. Configure Kernel Options:
launch kernel configuration interface:
make menuconfig
Within this interface, we ensured the following options were enabled:
– Kernel Debugging Support
– Debug Memory Allocation
– Kernel Memory Leak Detection ( CONFIG_DEBUG_KMEMLEAK=y )
3. Verify the Configuration:
After configuration, check `.config` file to confirm that `kmemleak` was enabled:
grep CONFIG_DEBUG_KMEMLEAK .config
✔ Modifying the `fscache` Source Code
To reproduce a memory leak scenario, we made a specific modification to the `fscache` code :
1. Edit `fs/fscache/stats.c`:
Modified the `fscache` statistics file to ensure that memory allocated for statistics was not released properly. We commented out the original release function in `fscache/stats.c`:
// Original code – old kernel bug
.release = seq_release,
// Modified code
.release = single_release,
✔ Compiling the Kernel
1. Configure the Kernel:
We set up the kernel with:
make oldconfig
2. Compile the Kernel:
We executed the compilation process:
make -j3
make modules_install
make install
✔ Mounting `debugfs`
mounting `debugfs` to enable access to debugging information:
sudo mount -t debugfs none /sys/kernel/debug
✔ Running the Test
To trigger the memory leak –
1. Reboot into the Compiled Kernel:
After installation, rebooting the system to utilize the new kernel.
2. Access the `fscache` Statistics:
Read the `fscache` statistics to prompt the allocation:
cat /proc/fs/fscache/stats
✔ Scanning for Memory Leaks
After executing operations that triggered allocations, run a scan with `kmemleak` to identify any unreferenced memory:
echo scan > /sys/kernel/debug/kmemleak
✔ Observing the Results
After scanning, we checked for any unreferenced objects reported by `kmemleak`:
cat /sys/kernel/debug/kmemleak
The output showed several unreferenced objects
unreferenced object 0xe996f570 (size 16):
comm “cat”, pid 2381, jiffies 42400 (age 1907.404s)
hex dump (first 16 bytes):
c0 9b 18 c1 00 9c 18 c1 e0 9b 18 c1 f0 7b af f8 ………….{..
backtrace:
[<c162313c>] kmemleak_alloc+0x3c/0xa0
[<c11578fe>] kmem_cache_alloc_trace+0x9e/0x130
[<c1189ea9>] single_open+0x29/0x90
[<f8af7be6>] fscache_stats_open+0x16/0x20 [fscache]
You can also write your own kernel module that intentionally leaks memory and captures the leak using Kmemleak. A screenshot illustrating this process is attached to the post.
𝐖𝐡𝐚𝐭 𝐢𝐬 𝐂𝐏𝐔 𝐈𝐬𝐨𝐥𝐚𝐭𝐢𝐨𝐧? 🤔
CPU Isolation is a Linux kernel feature that designates specific CPUs as isolated from general-purpose scheduling. Isolated CPUs do not handle regular workloads; instead, they focus on specialized tasks like real-time processing. This reduces interruptions and leads to lower latencies and more predictable performance.
𝐖𝐡𝐚𝐭 𝐢𝐬 𝐭𝐡𝐞 𝐧𝐨𝐡𝐳_𝐟𝐮𝐥𝐥 𝐅𝐞𝐚𝐭𝐮𝐫𝐞? ⏱️
The nohz_full feature allows certain CPUs to enter a “no-tick” mode, where they don’t receive timer interrupts. This is beneficial for low-latency scenarios, such as real-time applications, by reducing timer interrupt overhead and improving performance.
𝐇𝐨𝐰 𝐈𝐭 𝐖𝐨𝐫𝐤𝐬:
In a standard system, the kernel sends timer interrupts to all CPUs for scheduling. These can cause context switches and overhead.
With nohz_full enabled, CPUs in no-tick mode only receive timer interrupts when absolutely necessary, allowing tasks to execute uninterrupted.
𝐖𝐡𝐲 𝐧𝐨𝐡𝐳_𝐟𝐮𝐥𝐥 𝐈𝐧𝐭𝐫𝐨𝐝𝐮𝐜𝐞𝐝? 💡
The nohz_full feature addresses the needs of real-time and high-performance applications that require predictable latencies.
🛄𝐈𝐭 𝐚𝐢𝐦𝐬 𝐭𝐨:
𝐑𝐞𝐝𝐮𝐜𝐞 𝐋𝐚𝐭𝐞𝐧𝐜𝐲: Eliminating timer interrupts significantly lowers task latency.
𝐈𝐦𝐩𝐫𝐨𝐯𝐞 𝐏𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞: Applications like multimedia processing and gaming benefit from reduced overhead.
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐑𝐞𝐚𝐥-𝐓𝐢𝐦𝐞 𝐀𝐩𝐩𝐥𝐢𝐜𝐚𝐭𝐢𝐨𝐧𝐬: It configures CPUs for real-time workloads.
𝐇𝐨𝐰 𝐂𝐏𝐔 𝐈𝐬𝐨𝐥𝐚𝐭𝐢𝐨𝐧 𝐚𝐧𝐝 𝐧𝐨𝐡𝐳_𝐟𝐮𝐥𝐥 𝐖𝐨𝐫𝐤 𝐓𝐨𝐠𝐞𝐭𝐡𝐞𝐫 🔗
When utilizing nohz_full, it is crucial to manage CPU isolation settings correctly:
𝐁𝐨𝐨𝐭 𝐂𝐏𝐔: The boot CPU (the CPU that initializes the kernel and starts the system) must not be included in the nohz_full mask. This is essential because the boot CPU handles critical tasks during the boot process, including initializing other CPUs and managing timers.
𝐇𝐨𝐮𝐬𝐞𝐤𝐞𝐞𝐩𝐢𝐧𝐠 𝐂𝐏𝐔𝐬: Are responsible for executing system tasks, such as timer management and scheduling. If the boot CPU is incorrectly isolated, it can lead to issues, such as kernel crashes during the boot process.
𝐑𝐞𝐥𝐚𝐭𝐞𝐝 𝐈𝐬𝐬𝐮𝐞𝐬 𝐚𝐧𝐝 𝐑𝐞𝐜𝐞𝐧𝐭 𝐂𝐡𝐚𝐧𝐠𝐞𝐬 🔧
🔴 A regression in the Linux kernel caused crashes when the boot CPU was included in the nohz_full mask.
𝐓𝐡𝐞 𝐫𝐞𝐜𝐞𝐧𝐭 𝐩𝐚𝐭𝐜𝐡:
🔴 𝐑𝐞𝐬𝐭𝐨𝐫𝐞𝐬 𝐂𝐡𝐞𝐜𝐤𝐬: Prevents the boot CPU from being included in the nohz_full mask for stability.
🔴 𝐔𝐩𝐝𝐚𝐭𝐞𝐬 𝐇𝐚𝐧𝐝𝐥𝐢𝐧𝐠 𝐨𝐟 𝐈𝐬𝐨𝐥𝐚𝐭𝐞𝐝 𝐂𝐏𝐔𝐬: Ensures the kernel can determine available CPUs without causing crashes.
𝐑𝐞𝐥𝐚𝐭𝐞𝐝 𝐋𝐢𝐧𝐤𝐬 𝐚𝐧𝐝 𝐅𝐮𝐫𝐭𝐡𝐞𝐫 𝐑𝐞𝐚𝐝𝐢𝐧𝐠📚
https://lnkd.in/gFAd6ypP
Samsung S10+/S9 kernel 4.14 (Android 10) Kernel Function Address (.text) and Heap Address Information Leak
In kernel development, precise data handling is not only about system performance but also crucial for security. Today, we delve into a significant vulnerability in the Linux kernel’s 𝐩𝐭𝐫𝐚𝐜𝐞_𝐩𝐞𝐞𝐤_𝐬𝐢𝐠𝐢𝐧𝐟𝐨() function, which was 𝐩𝐫𝐞𝐯𝐢𝐨𝐮𝐬𝐥𝐲 𝐮𝐬𝐢𝐧𝐠 𝐢𝐧𝐭32 𝐟𝐨𝐫 𝐨𝐟𝐟𝐬𝐞𝐭𝐬 𝐛𝐮𝐭 𝐧𝐨𝐰 𝐰𝐢𝐬𝐞𝐥𝐲 𝐮𝐬𝐞𝐬 𝐮𝐧𝐬𝐢𝐠𝐧𝐞𝐝 𝐥𝐨𝐧𝐠.
🔴 𝐩𝐭𝐫𝐚𝐜𝐞: Add ability to retrieve signals without removing from a queue
https://lnkd.in/g3m8459V
🔴 𝐬𝐢𝐠𝐧𝐚𝐥/𝐩𝐭𝐫𝐚𝐜𝐞: 𝐃𝐨𝐧’𝐭 𝐥𝐞𝐚𝐤 𝐮𝐧𝐢𝐭𝐢𝐚𝐥𝐢𝐳𝐞𝐝 𝐤𝐞𝐫𝐧𝐞𝐥 𝐦𝐞𝐦𝐨𝐫𝐲 𝐰𝐢𝐭𝐡 𝐏𝐓𝐑𝐀𝐂𝐄_𝐏𝐄𝐄𝐊_𝐒𝐈𝐆𝐈𝐍𝐅𝐎
https://lnkd.in/g4JYbqQi
𝐅𝐨𝐫 𝐦𝐨𝐫𝐞 𝐢𝐧𝐟𝐨 𝐚𝐛𝐨𝐮𝐭 𝐭𝐡𝐢𝐬 𝐢𝐬𝐬𝐮𝐞 𝐩𝐥𝐞𝐚𝐬𝐞 𝐜𝐡𝐞𝐜𝐤 ->
https://lnkd.in/gS593p5M
The original implementation of the 𝐩𝐭𝐫𝐚𝐜𝐞_𝐩𝐞𝐞𝐤_𝐬𝐢𝐠𝐢𝐧𝐟𝐨() function used an int32 type -> s32 off = arg.off + i;
This choice was problematic for two reasons:
1. 𝐒𝐞𝐜𝐮𝐫𝐢𝐭𝐲 𝐑𝐢𝐬𝐤 𝐟𝐫𝐨𝐦 𝐍𝐞𝐠𝐚𝐭𝐢𝐯𝐞 𝐎𝐟𝐟𝐬𝐞𝐭𝐬: Allowing negative values could lead to unauthorized memory access, posing a severe security risk.
2. 𝐈𝐧𝐚𝐝𝐞𝐪𝐮𝐚𝐭𝐞 𝐑𝐚𝐧𝐠𝐞 𝐟𝐨𝐫 𝐒𝐲𝐬𝐭𝐞𝐦 𝐒𝐜𝐚𝐥𝐚𝐛𝐢𝐥𝐢𝐭𝐲: The limited range of `int32` could lead to data truncation in systems managing extensive data sets.
To mitigate these risks, the function now employs `unsigned long` for the offset:
unsigned long off = arg.off + i;
This update addresses the core issues by:
– 𝐄𝐥𝐢𝐦𝐢𝐧𝐚𝐭𝐢𝐧𝐠 𝐍𝐞𝐠𝐚𝐭𝐢𝐯𝐞 𝐕𝐚𝐥𝐮𝐞𝐬: Ensuring all offsets are non-negative to prevent potential security breaches through erroneous memory access.
– 𝐄𝐱𝐩𝐚𝐧𝐝𝐢𝐧𝐠 𝐭𝐡𝐞 𝐏𝐨𝐬𝐬𝐢𝐛𝐥𝐞 𝐑𝐚𝐧𝐠𝐞: Accommodating larger values to enhance system stability & scalability.
Using `unsigned long` not only prevents common buffer overflows & vulnerabilities associated with out-of-bound access but is also pivotal in safeguarding against specific exploits that could leak sensitive information such as kernel addresses. 𝐓𝐡𝐢𝐬 𝐯𝐮𝐥𝐧𝐞𝐫𝐚𝐛𝐢𝐥𝐢𝐭𝐲 𝐰𝐚𝐬 𝐧𝐨𝐭𝐚𝐛𝐥𝐲 𝐝𝐞𝐦𝐨𝐧𝐬𝐭𝐫𝐚𝐭𝐞𝐝 𝐭𝐡𝐫𝐨𝐮𝐠𝐡 𝐚 𝐩𝐫𝐨𝐨𝐟 𝐨𝐟 𝐜𝐨𝐧𝐜𝐞𝐩𝐭 𝐭𝐡𝐚𝐭 𝐜𝐨𝐮𝐥𝐝 𝐥𝐞𝐚𝐤 𝐚𝐝𝐝𝐫𝐞𝐬𝐬𝐞𝐬 𝐟𝐫𝐨𝐦 𝐭𝐡𝐞 𝐤𝐞𝐫𝐧𝐞𝐥 𝐡𝐞𝐚𝐩 𝐚𝐧𝐝 𝐭𝐡𝐞 `.𝐭𝐞𝐱𝐭` 𝐬𝐞𝐜𝐭𝐢𝐨𝐧, 𝐜𝐫𝐮𝐜𝐢𝐚𝐥𝐥𝐲 𝐞𝐱𝐩𝐨𝐬𝐢𝐧𝐠 𝐭𝐡𝐞 𝐬𝐭𝐫𝐮𝐜𝐭 𝐭𝐚𝐬𝐤_𝐬𝐭𝐫𝐮𝐜𝐭.
This critical update in the 𝐩𝐭𝐫𝐚𝐜𝐞_𝐩𝐞𝐞𝐤_𝐬𝐢𝐠𝐢𝐧𝐟𝐨() function is a prime example of proactive security measures essential in operating system development.
Are you fascinated by the inner workings of the Linux Kernel and eager to dive deep into the world of Kernel Debugging? 🐧💻
In our latest YouTube video, we’ve put together a comprehensive guide on “Enabling KGDB for Kernel Debugging.” 🛠️🔍
https://lnkd.in/gKSVMbcp
✅ Step-by-step instructions on enabling KGDB for Kernel Debugging.
✅ How to configure the kernel for debugging purposes.
✅ Insights into Kernel Debugging techniques and tools.
✅ Tips and tricks for effective Kernel Debugging.
Join us on this informative journey as we unravel the mysteries of Kernel Debugging. 🤓🕵️♂️
But that’s not all! To stay updated on Linux Kernel Development, Device Drivers, and more, we invite you to join our LinkedIn Group:
🌐👥 Linux Kernel &LDD -> https://lnkd.in/gGswGTwj
Connect with fellow Kernel enthusiasts, share your insights, and explore the world of Linux Kernel together! 🌟🚀
Don’t miss out on this opportunity to enhance your Kernel Debugging skills. Watch the video, join our group, and let’s dive deep into the fascinating world of Linux Kernel Development! 🎉🐧
🌐 Maurice J. Bach’s “Design of the Unix Operating System” offers a timeless exploration of the internal algorithms and structures that serve as the foundation of Unix & Unix like system. Despite being a bit dated, the book is a valuable resource for comprehending the intricate workings of the Unix kernel.
System Programmers: A comprehensive reference for system programmers, providing insights into the kernel’s functionality and facilitating comparisons with algorithms in other operating systems.
UNIX Programmers: Offers UNIX programmers a deeper understanding of their programs’ interaction with the system, enabling them to write more efficient and sophisticated code.
Linux Kernel and Device Driver Developers: Valuable for developers working on the Linux kernel and device drivers, providing foundational insights into operating system design and implementation.
Students: Ideal for advanced undergraduates and first-year graduate students studying operating systems. The book serves as an excellent textbook, allowing students to delve into the internals of the operating system.
⭐ The book originated from a course at AT&T Bell Laboratories in 1983-1984, emphasizing source code exploration.
⭐ Focuses on mastering algorithmic concepts before delving into source code, enhancing comprehension.
⭐ Descriptions of algorithms are kept simple, mirroring the elegance of the Unix system.
⭐ Utilizes C-like pseudo-code for algorithm presentations, aiding natural language descriptions.
⭐ Features figures illustrating relationships between data structures manipulated by the system.
⭐ Later chapters include small C programs, offering practical insights into system concepts.
The book does not provide a line-by-line rendition of the system in English but describes the general flow of algorithms. Names of algorithms correspond to procedure names in the kernel, enhancing clarity.
Small C programs in later chapters illustrate system concepts as experienced by users. Examples, although not error-checking, run on System V and should be compatible with other versions of the system.
📖 While the book may be considered “old,” its enduring value lies in unraveling the fundamental principles of Unix. It’s a must-read for those seeking a deeper understanding of operating system internals, with the caveat that some details may differ from contemporary Linux systems due to design changes. Embrace the simplicity and elegance embedded in the Unix design through Maurice J. Bach’s insightful work.
Free Access: 📖 Design of the Unix Operating System ( https://lnkd.in/gUEfU9iU ) – Looks like the PDF is available for free!
🚀 Bonus: Sample PDF attached shows pseudo code of msgsnd and msgrcv algorithms.
This book explores foundational principles and implementations based on older kernel versions like V2.2, offering insights into memory management, booting processes, and BIOS-related info. Despite its divergence from the latest code, it’s a goldmine for understanding Linux’s evolutionary journey.
🌟 Emphasizing the significance of simpler OS models, it highlights Linux 0.11 (less than 20,000 lines of code) as a key learning tool. Even with Linux’s current complexity, the core design concepts remain relevant, making learning from Linux 0.11 both practical and insightful.
Initial chapters detail BIOS booting, process creation, and file system interactions.
Subsequent sections dive into user processes, memory management, file operations, and more.
The final section elaborates on key mechanisms like protection, privilege levels, and interruptions, illuminating their role in system architecture.
🌐 Translated by Dr. Tingshao Zhu, this book connects theory with practice, presenting real code and cases to demystify OS design. An essential read for tech enthusiasts seeking a profound understanding of OS design and Linux Kernel’s foundational concepts!
🌐 Translated by Dr. Tingshao Zhu, this book connects theory with practice, presenting real code and cases to demystify OS design. An essential read for tech enthusiasts seeking a profound understanding of OS design and Linux Kernel’s foundational concepts!
