
Mastering the use of `void` in C functions is crucial for embedded engineers at all levels. Here are key interview questions and what interviewers expect:
𝐈𝐧𝐭𝐞𝐫𝐯𝐢𝐞𝐰 𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧𝐬 & 𝐄𝐱𝐩𝐞𝐜𝐭𝐞𝐝 𝐊𝐧𝐨𝐰𝐥𝐞𝐝𝐠𝐞
1. 𝐂𝐨𝐝𝐞 𝐑𝐞𝐯𝐢𝐞𝐰 𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧:
void cleanup_system(void) {
close(fd);
pthread_mutex_unlock(&mutex);
free(ptr);
}
𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧: “What’s wrong with this cleanup function? How would you improve it with proper void usage?”
𝐈𝐧𝐭𝐞𝐫𝐯𝐢𝐞𝐰𝐞𝐫 𝐄𝐱𝐩𝐞𝐜𝐭𝐬:
– Recognition that close() and pthread_mutex_unlock() return values need handling
– Knowledge of (void) casting for intentionally ignored returns
– Understanding that free() doesn’t need casting as it returns void
– Proper error handling or explicit ignoring with (void)
2. 𝐅𝐮𝐧𝐜𝐭𝐢𝐨𝐧 𝐈𝐦𝐩𝐥𝐞𝐦𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧 𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧:
void register_callback(void (*handler)(void));
𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧: “Implement both the callback function and registration handler that would match this prototype.”
𝐈𝐧𝐭𝐞𝐫𝐯𝐢𝐞𝐰𝐞𝐫 𝐄𝐱𝐩𝐞𝐜𝐭𝐬:
– Proper function pointer syntax
– Function taking no parameters (void)
– NULL pointer checking in implementation
– Clear understanding of callback mechanisms
3. 𝐄𝐫𝐫𝐨𝐫 𝐇𝐚𝐧𝐝𝐥𝐢𝐧𝐠 𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧:
int mutex_lock(void);
int mutex_unlock(void);
void critical_section(void) {
mutex_lock();
// … some operations
mutex_unlock();
}
𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧: “This code has two issues related to void usage. Identify and fix them.”
𝐈𝐧𝐭𝐞𝐫𝐯𝐢𝐞𝐰𝐞𝐫 𝐄𝐱𝐩𝐞𝐜𝐭𝐬:
– Recognition that lock() return value must be checked
– Understanding that unlock() can be cast to (void)
– Proper error handling implementation
– Knowledge of critical section safety
4. 𝐅𝐮𝐧𝐜𝐭𝐢𝐨𝐧 𝐃𝐞𝐜𝐥𝐚𝐫𝐚𝐭𝐢𝐨𝐧 𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧:
void process_data() { … }
void process_data(void) { … }
(void)process_data();
𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧: “Explain the differences between these three uses of void.”
𝐈𝐧𝐭𝐞𝐫𝐯𝐢𝐞𝐰𝐞𝐫 𝐄𝐱𝐩𝐞𝐜𝐭𝐬:
– Understanding of K&R vs modern C style
– Knowledge of parameter safety differences
– Recognition of return value casting purpose
– Clear explanation of when to use each
5. 𝐒𝐲𝐬𝐭𝐞𝐦 𝐃𝐞𝐬𝐢𝐠𝐧 𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧:
𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧: “Implement a thread-safe cleanup function that:
– Takes no parameters
– Ignores cleanup operation return values safely
– Follows modern C coding standards”
𝐈𝐧𝐭𝐞𝐫𝐯𝐢𝐞𝐰𝐞𝐫 𝐄𝐱𝐩𝐞𝐜𝐭𝐬:
– Proper (void) parameter usage
– Explicit return value handling
– Thread-safety implementation
– Modern C coding standards compliance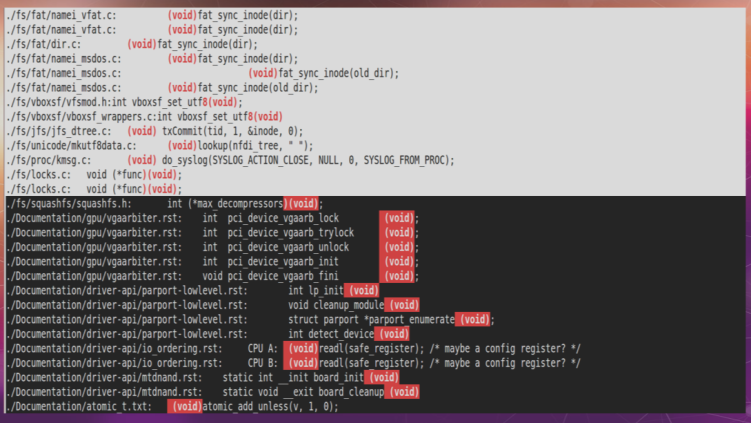
1. 𝐋𝐨𝐜𝐤𝐢𝐧𝐠 𝐚𝐧𝐝 𝐑𝐚𝐜𝐞 𝐂𝐨𝐧𝐝𝐢𝐭𝐢𝐨𝐧𝐬
𝐑𝐚𝐜𝐞 𝐂𝐨𝐧𝐝𝐢𝐭𝐢𝐨𝐧𝐬:
▪️ A race condition occurs when multiple threads/processes access shared resources simultaneously without proper synchronization.
▪️ Can lead to data corruption, inconsistent states, and unpredictable behavior.
Example of a Race Condition:
Thread 1 Thread 2
——– ——–
read value X=5
read value X=5
increment X=6
increment X=6
write back X
write back X
// X is incremented only once instead of twice!
𝐓𝐲𝐩𝐞𝐬 𝐨𝐟 𝐋𝐨𝐜𝐤𝐬 𝐢𝐧 𝐋𝐢𝐧𝐮𝐱:
Mutex
Spinlock
RW Semaphore
RCU (Read-Copy-Update)
Sequence Lock
2. 𝐅𝐨𝐫𝐤 𝐎𝐩𝐞𝐫𝐚𝐭𝐢𝐨𝐧 𝐢𝐧 𝐋𝐢𝐧𝐮𝐱
𝐖𝐡𝐚𝐭 𝐢𝐬 𝐟𝐨𝐫𝐤()?
▪️ Creates a new process by duplicating the calling process
▪️ Child process gets a copy of parent’s memory space
▪️ Copy-on-Write (CoW) optimization used
𝐅𝐨𝐫𝐤 𝐒𝐭𝐞𝐩𝐬 :
Create new task structure
Copy process credentials
Create new memory descriptor
Copy page tables
Copy VMAs (Virtual Memory Areas)
Setup CoW mechanisms
Copy file descriptors
Copy other resources
𝐊𝐞𝐲 𝐂𝐨𝐝𝐞 𝐏𝐚𝐭𝐡:
sys_fork()
→ kernel_clone()
→ copy_mm()
→ dup_mm()
→ dup_mmap() // 𝐕𝐌𝐀 𝐜𝐨𝐩𝐲𝐢𝐧𝐠 𝐡𝐚𝐩𝐩𝐞𝐧𝐬
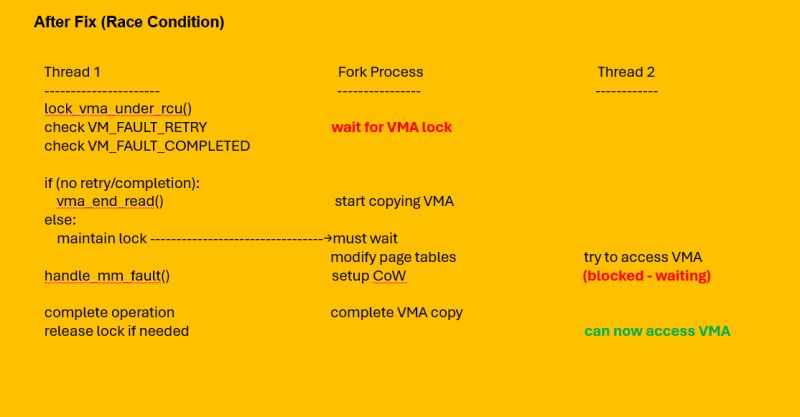
3. 𝐕𝐌𝐀 𝐑𝐚𝐜𝐞 𝐂𝐨𝐧𝐝𝐢𝐭𝐢𝐨𝐧 𝐚𝐧𝐝 𝐅𝐢𝐱
𝐕𝐢𝐫𝐭𝐮𝐚𝐥 𝐌𝐞𝐦𝐨𝐫𝐲 𝐀𝐫𝐞𝐚𝐬 (𝐕𝐌𝐀𝐬):
▪️ Represent contiguous virtual memory regions
▪️ Contain permissions, flags, and mapping information
▪️ Managed in mm_struct of each process
▪️ The Race Condition:
▪️ Problem scenario during fork:
𝐂𝐨𝐝𝐞 (𝐰𝐢𝐭𝐡 𝐫𝐚𝐜𝐞, 𝐢𝐧 𝐦𝐮𝐥𝐭𝐢𝐭𝐡𝐫𝐞𝐚𝐝 𝐬𝐜𝐞𝐧𝐚𝐫𝐢𝐨 ) –
vma = lock_vma_under_rcu(mm, address);
fault = handle_mm_fault(vma, address, flags);
vma_end_read(vma); // Release too early
if (!(fault & VM_FAULT_RETRY)) {
// Check conditions after release
}
𝐅𝐢𝐱𝐞𝐝 𝐜𝐨𝐝𝐞 –
vma = lock_vma_under_rcu(mm, address);
fault = handle_mm_fault(vma, address, flags);
if (!(fault & (VM_FAULT_RETRY | VM_FAULT_COMPLETED)))
vma_end_read(vma); // Only release if no retry/completion needed
𝐑𝐞𝐩𝐫𝐨𝐝𝐮𝐜𝐞𝐫 𝐏𝐫𝐨𝐠𝐫𝐚𝐦:
// Example of problematic code pattern
for (i = 0; i != 2; i += 1)
clone(&thread, &stacks[i] + 1, CLONE_THREAD | CLONE_VM | CLONE_SIGHAND, NULL);
while (1) {
if (fork() == 0) _exit(0);
(void)wait(NULL);
}

In cybersecurity, Return-Oriented Programming (ROP) and Jump-Oriented Programming (JOP) are techniques that allow attackers to hijack a program’s control flow. These attacks reuse existing code snippets (gadgets) instead of injecting new code, making them harder to detect and defend against.
𝐑𝐞𝐭𝐮𝐫𝐧-𝐎𝐫𝐢𝐞𝐧𝐭𝐞𝐝 𝐏𝐫𝐨𝐠𝐫𝐚𝐦𝐦𝐢𝐧𝐠 (𝐑𝐎𝐏):
ROP exploits buffer overflow vulnerabilities to overwrite a function’s return address, redirecting execution to gadgets in memory.
𝐉𝐮𝐦𝐩-𝐎𝐫𝐢𝐞𝐧𝐭𝐞𝐝 𝐏𝐫𝐨𝐠𝐫𝐚𝐦𝐦𝐢𝐧𝐠 (𝐉𝐎𝐏)
JOP is similar but targets indirect jumps instead of returns, making it more versatile than ROP.
These attacks bypass traditional defenses like DEP (Data Execution Prevention) and ASLR (Address Space Layout Randomization), requiring more advanced protection techniques.
🔐 𝐏𝐫𝐨𝐭𝐞𝐜𝐭𝐢𝐧𝐠 𝐀𝐠𝐚𝐢𝐧𝐬𝐭 𝐑𝐎𝐏 𝐚𝐧𝐝 𝐉𝐎𝐏 🔐
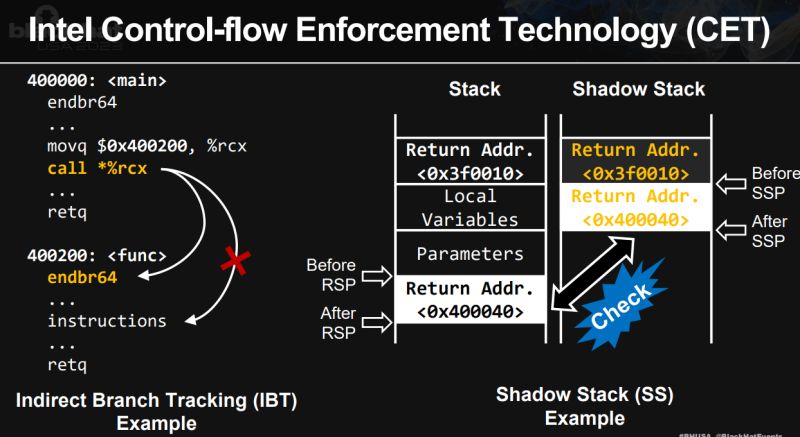
1️⃣ Control-Flow Integrity (CFI):
CFI ensures that function calls and jumps in a program only occur at valid, predefined locations, preventing attacks like ROP and JOP.
2️⃣ Intel Control-Flow Enforcement Technology (CET):
Intel’s CET is a hardware-based defense with two key components:
Indirect Branch Tracking (IBT): Ensures indirect branches target valid locations marked with ENDBR instructions.
𝐒𝐡𝐚𝐝𝐨𝐰 𝐒𝐭𝐚𝐜𝐤 (𝐒𝐒): Verifies return addresses match expected values.
CET offers strong protection with minimal performance overhead.
hashtag#KernelConfiguration
CONFIG_X86_IBT=y # Enable Intel IBT
CONFIG_CPU_UNRET_ENTRY=y # Enable CET shadow stack
hashtag#Forx86
CONFIG_X86_IBT=y # Intel IBT
CONFIG_X86_KERNEL_IBT=y # Kernel IBT support
3️⃣ Clang/LLVM kCFI:
For environments lacking hardware support, Clang/LLVM kCFI provides software-based protection by adding control-flow checks at compile time.
CONFIG_CFI_CLANG=y # Enable Clang CFI
CONFIG_CFI_PERMISSIVE=n # Strict mode (not permissive)
CONFIG_CFI_CLANG_SHADOW=y # Enable shadow call stack
⚠️ 𝐖𝐞𝐚𝐤𝐧𝐞𝐬𝐬𝐞𝐬 𝐢𝐧 𝐊𝐞𝐫𝐧𝐞𝐥 𝐂𝐅𝐈 𝐃𝐞𝐟𝐞𝐧𝐬𝐞𝐬 – 𝐏𝐎𝐏 ⚠️
While CFI, Intel CET, and Clang/LLVM kCFI offer strong protections, 𝐏𝐚𝐠𝐞-𝐎𝐫𝐢𝐞𝐧𝐭𝐞𝐝 𝐏𝐫𝐨𝐠𝐫𝐚𝐦𝐦𝐢𝐧𝐠 (𝐏𝐎𝐏) 𝐛𝐲𝐩𝐚𝐬𝐬𝐞𝐬 𝐭𝐡𝐞𝐬𝐞 𝐝𝐞𝐟𝐞𝐧𝐬𝐞𝐬. POP exploits writable page tables in kernel memory, allowing attackers to remap pages and create new control flows using legitimate code within the kernel. This makes it harder for current CFI mechanisms to detect or block the exploit.
For more info – https://shorturl.at/tNKml
Every kernel developer, from beginner to expert, will encounter these fundamental functions. Handling one of the most critical operations in Linux: secure data transfer between user space and kernel space.
copy_from_user() // Userspace → Kernel
copy_to_user() // Kernel → Userspace
1. 2002: The Early Days – Simple but Dangerous (Linux 2.4)
static __inline__ unsigned long copy_from_user(void *to, const void *from, unsigned long n)
{
if (access_ok(VERIFY_READ, from, n))
__do_copy_from_user(to, from, n);
else
memzero(to, n); // Dangerous with negative n!
return n;
}
Why Changed:
– Initial attempt at memory safety
– Could wipe gigabytes with negative numbers
– No size validation
2. 2005: First Size Check (Linux 2.6)
static inline int copy_from_user(…) {
if (unlikely(n > INT_MAX))
BUG(); // Hard stop for large sizes
return __copy_from_user(to, from, n);
}
Why Changed:
– Added overflow protection
– Prevented large buffer attacks
3. 2009: Compiler-Assisted Protection (Linux 2.6)
static inline unsigned long copy_from_user(void *to, const void __user *from, unsigned long n)
{
int sz = __compiletime_object_size(to);
int ret = -EFAULT;
if (likely(sz == -1 || sz >= n))
ret = _copy_from_user(to, from, n);
else
WARN(1, “Buffer overflow detected!\n”);
return ret;
}
Why Changed:
– Added compile-time checks
– Buffer overflow detection
– x86 architecture improvements
4. 2013: copy_to_user Enhancement (Linux 3.13)
static inline unsigned long copy_to_user(void __user *to, const void *from, unsigned long n)
{
int sz = __compiletime_object_size(from);
might_fault();
if (likely(sz < 0 || sz >= n))
n = _copy_to_user(to, from, n);
else if(__builtin_constant_p(n))
copy_to_user_overflow();
else
__copy_to_user_overflow(sz, n);
return n;
}
Why Changed:
– Symmetric protection for data output
– Prevented kernel data leaks
– Better compile-time validations
5. 2016: The Hardening Revolution (Linux 4.8)
static __always_inline bool check_copy_size(const void *addr, size_t bytes, bool is_source)
{
int sz = __compiletime_object_size(addr);
if (unlikely(sz >= 0 && sz < bytes)) {
if (!__builtin_constant_p(bytes))
copy_overflow(sz, bytes);
return false;
}
check_object_size(addr, bytes, is_source);
return true;
}
Why Changed:
– Complete heap validation
– Object bounds checking
– Architecture-independent security
6. 2019: Modern Protection (Linux 5.5)
static __always_inline bool check_copy_size(const void *addr, size_t bytes, bool is_source)
{
// Previous checks plus:
if (WARN_ON_ONCE(bytes > INT_MAX))
return false;
check_object_size(addr, bytes, is_source);
return true;
}
For more Info –
https://lnkd.in/gG6WrCCV
How the Linux kernel efficiently manages millions of small object allocations? Let’s dive deep into the SLUB (Simple List of Used Blocks) allocator, the 𝐛𝐚𝐜𝐤𝐛𝐨𝐧𝐞 𝐨𝐟 𝐋𝐢𝐧𝐮𝐱 𝐤𝐞𝐫𝐧𝐞𝐥 𝐦𝐞𝐦𝐨𝐫𝐲 𝐦𝐚𝐧𝐚𝐠𝐞𝐦𝐞𝐧𝐭! 🐧
𝐓𝐞𝐜𝐡𝐧𝐢𝐜𝐚𝐥 𝐃𝐞𝐞𝐩-𝐃𝐢𝐯𝐞:
𝐂𝐨𝐫𝐞 𝐀𝐫𝐜𝐡𝐢𝐭𝐞𝐜𝐭𝐮𝐫𝐞 🏗️
The SLUB allocator implements a sophisticated multi-tiered strategy:
𝐀𝐥𝐥𝐨𝐜𝐚𝐭𝐢𝐨𝐧 𝐏𝐚𝐭𝐡𝐬
🚀 Fast-path (Primary):
if (likely(freelist)) {
return freelist; // Direct hit: ~10-20 cycles
}
⚡ Medium-paths:
– CPU page-freelist
– Partial lists
– Node-level operations
– Typical overhead: 100-500 cycles
🔄 Slow-path (Fallback):
– Buddy allocator interaction
– Full page allocation
– Slab initialization
– Cost: 1000+ cycles
2. 𝐀𝐝𝐯𝐚𝐧𝐜𝐞𝐝 𝐅𝐞𝐚𝐭𝐮𝐫𝐞𝐬 🛠️
▪️ Memory Organization:
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
unsigned long flags;
int size; // The size of objects
int object_size; // Aligned object size
int offset; // Free pointer offset
};
▪️ Security Mechanisms:
🛡️ Protection Features:
– Freelist pointer encryption
– Memory poisoning (0xA5)
– Red-zoning for overflow detection
– FreeList randomization
3. 𝐃𝐞𝐛𝐮𝐠𝐠𝐢𝐧𝐠 & 𝐌𝐨𝐧𝐢𝐭𝐨𝐫𝐢𝐧𝐠 🔍
▪️ Runtime Analysis:
Enable debugging
echo 1 > /sys/kernel/slab/kmalloc-1024/trace
Monitor statistics
cat /proc/slabinfo
▪️ 𝐏𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞 𝐓𝐨𝐨𝐥𝐬:
– kmem_cache_flags
– slabinfo statistics
– Memory leak tracking
– Allocation pattern analysis
4. 𝐑𝐞𝐚𝐥-𝐖𝐨𝐫𝐥𝐝 𝐀𝐩𝐩𝐥𝐢𝐜𝐚𝐭𝐢𝐨𝐧𝐬 💻
▪️ Common Use Cases:
– Network packet buffers (skbuff)
– File system caches (dentry, inode)
– Process descriptors (task_struct)
– Device driver allocations
▪️ Performance Impact:
– Critical path optimization
– Cache-line alignment
– NUMA awareness
– Memory fragmentation prevention
5. 𝐁𝐞𝐬𝐭 𝐏𝐫𝐚𝐜𝐭𝐢𝐜𝐞𝐬 & 𝐓𝐢𝐩𝐬 📌
▪️ Development Guidelines:
– Align object sizes to cache lines
– Use appropriate GFP flags
– Implement proper error handling
– Consider NUMA topology
▪️ Troubleshooting:
– Memory leak detection
– Fragmentation analysis
– Performance profiling
– Debug flag usage
💡𝐓𝐢𝐩𝐬:
1. Use SLAB_HWCACHE_ALIGN for hot paths
2. Implement bulk allocation for better performance
3. Consider using per-CPU caches for high-frequency allocations
4. Monitor partial lists for fragmentation
𝐑𝐞𝐚𝐥-𝐖𝐨𝐫𝐥𝐝 𝐈𝐦𝐩𝐚𝐜𝐭:
– Critical for container orchestration
– Essential for high-performance networking
– Fundamental to filesystem performance
– Key to system stability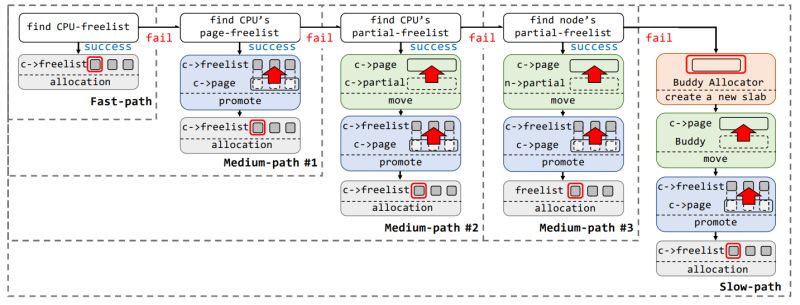
Looking for the best full stack course to kickstart your tech career? You’re in the right place. Full stack developers are among the most sought-after professionals in today’s tech industry, with companies actively seeking versatile developers who can handle both front-end and back-end development.
In this comprehensive guide, we’ll explore the best full stack online courses available in 2024, with a special focus on programs offering job placement support. Whether you’re a beginner or an experienced developer looking to upskill, this guide will help you choose the perfect course for your career goals.
Before diving into the course options, here’s what to look for:

Expertifie offers one of the most comprehensive full stack development courses with both self-paced and live learning options. Their program stands out for its practical approach and strong focus on job placement.
Key Features:
Course Duration:
Course Fees: 75,000 INR
Best For: Both beginners and working professionals looking to transition into full stack development
Placement Support:
Scaler Academy offers a structured approach to learning full stack development with different tracks for varying experience levels.
Key Features:
Course Duration:9.5-11.5 months
Best For: Learners at all experience levels
Placement Support:
Udacity’s program focuses on practical skills with real-world projects and expert feedback.
Key Features:
Course Duration:4 months
Fees: $1,356 or $339/month
Placement Support:
Springboard offers a comprehensive bootcamp with a job guarantee.
Key Features:
Course Duration:9 months
Fees: $10,900 (upfront) or $1,211/month
Placement Support:
IBM’s program offers a comprehensive curriculum with a focus on cloud-native development.
Key Features:
Course Duration:4 months
Fees: $39/month
Placement Support:
Simplilearn’s program, in collaboration with Caltech CTME, offers comprehensive full stack training.
Key Features:
Course Duration:9 months
Fees: ₹99,999
Placement Support:
UpGrad’s intensive bootcamp focuses on practical skills and career readiness.
Key Features:
Course Duration:13 weeks
Fees: ₹99,000 + GST
Placement assistance:
Consider these factors when selecting your course:
Full stack developers can expect:
Investing in a full stack development course is a smart career move in 2024. With options ranging from self-paced learning to intensive bootcamps, there’s a program for every learning style and career goal. Expertifie’s comprehensive program stands out for its flexible learning options and strong placement support, making it an excellent choice for aspiring full stack developers.
Remember to carefully evaluate each course based on your specific needs, schedule, and career objectives. The right course will not only teach you the technical skills but also prepare you for a successful career in full stack development.
Would you like to learn more about any specific course or have questions about starting your full stack development journey? Feel free to reach out in the comments below!
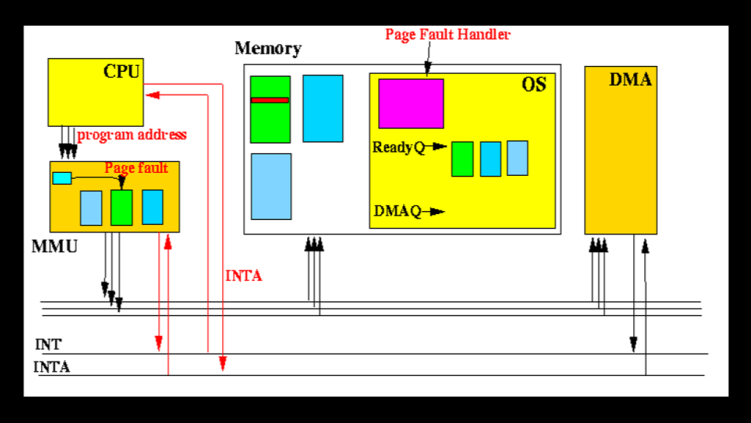
Ever wondered how Linux handles memory access in critical sections where even a millisecond of delay could spell disaster? Enter `pagefault_disabled`, a fascinating kernel feature that’s like a traffic controller for memory faults.
“𝐒𝐨𝐦𝐞𝐭𝐢𝐦𝐞𝐬 𝐭𝐡𝐞 𝐫𝐢𝐠𝐡𝐭 𝐭𝐡𝐢𝐧𝐠 𝐭𝐨 𝐝𝐨 𝐢𝐬 𝐭𝐨 𝐣𝐮𝐬𝐭 𝐟𝐚𝐢𝐥. 𝐇𝐚𝐯𝐢𝐧𝐠 𝐚 𝐩𝐚𝐠𝐞 𝐟𝐚𝐮𝐥𝐭 𝐡𝐚𝐧𝐝𝐥𝐞𝐫 𝐭𝐡𝐚𝐭 𝐭𝐫𝐢𝐞𝐬 𝐭𝐨 𝐛𝐞 𝐭𝐨𝐨 𝐜𝐥𝐞𝐯𝐞𝐫 𝐢𝐬 𝐰𝐨𝐫𝐬𝐞 𝐭𝐡𝐚𝐧 𝐨𝐧𝐞 𝐭𝐡𝐚𝐭 𝐣𝐮𝐬𝐭 𝐬𝐚𝐲𝐬 ‘𝐧𝐨’ 𝐪𝐮𝐢𝐜𝐤𝐥𝐲.”
Imagine you’re in the middle of handling a hardware interrupt, and suddenly you need to access some memory. What happens if that memory isn’t readily available? Normally, the kernel would happily pause, load the memory from disk, and continue. But in an interrupt handler? That would be catastrophic!
This is where `𝐜𝐮𝐫𝐫𝐞𝐧𝐭->𝐩𝐚𝐠𝐞𝐟𝐚𝐮𝐥𝐭_𝐝𝐢𝐬𝐚𝐛𝐥𝐞𝐝` comes in. It’s like putting up a “Do Not Disturb” sign for memory management. When enabled, it tells the kernel: “Don’t try to be helpful – if something goes wrong, fail fast!”
pagefault_disable(); // “Do Not Disturb” sign goes up
// Critical operation that can’t afford to sleep
pagefault_enable(); // Back to normal
“𝐓𝐡𝐞 𝐩𝐚𝐠𝐞𝐟𝐚𝐮𝐥𝐭_𝐝𝐢𝐬𝐚𝐛𝐥𝐞𝐝() 𝐦𝐞𝐜𝐡𝐚𝐧𝐢𝐬𝐦 𝐢𝐬 𝐨𝐧𝐞 𝐨𝐟 𝐭𝐡𝐨𝐬𝐞 𝐬𝐮𝐛𝐭𝐥𝐞 𝐲𝐞𝐭 𝐜𝐫𝐢𝐭𝐢𝐜𝐚𝐥 𝐟𝐞𝐚𝐭𝐮𝐫𝐞𝐬 𝐭𝐡𝐚𝐭 𝐦𝐚𝐤𝐞𝐬 𝐭𝐡𝐞 𝐝𝐢𝐟𝐟𝐞𝐫𝐞𝐧𝐜𝐞 𝐛𝐞𝐭𝐰𝐞𝐞𝐧 𝐚 𝐤𝐞𝐫𝐧𝐞𝐥 𝐭𝐡𝐚𝐭 𝐰𝐨𝐫𝐤𝐬 𝐚𝐧𝐝 𝐨𝐧𝐞 𝐭𝐡𝐚𝐭 𝐰𝐨𝐫𝐤𝐬 𝐫𝐞𝐥𝐢𝐚𝐛𝐥𝐲.”
It’s a simple counter in each task’s structure, but its impact is profound. With this mechanism, Linux can safely:
– Handle hardware interrupts
– Access device registers
– Perform atomic operations
– Manage critical sections
Want to dive deep into how this mechanism works? Check out the detailed technical explanation covers everything ( from x86 architecture specifics to real-world usage patterns. )
𝐑𝐞𝐦𝐞𝐦𝐛𝐞𝐫: 𝐈𝐧 𝐭𝐡𝐞 𝐤𝐞𝐫𝐧𝐞𝐥, 𝐬𝐨𝐦𝐞𝐭𝐢𝐦𝐞𝐬 𝐟𝐚𝐢𝐥𝐢𝐧𝐠 𝐟𝐚𝐬𝐭 𝐢𝐬 𝐛𝐞𝐭𝐭𝐞𝐫 𝐭𝐡𝐚𝐧 𝐭𝐫𝐲𝐢𝐧𝐠 𝐭𝐨𝐨 𝐡𝐚𝐫𝐝!