
𝐅𝐨𝐫 𝐞𝐱𝐚𝐦𝐩𝐥𝐞 𝐢𝐧 𝐭𝐡𝐞 𝐛𝐞𝐥𝐨𝐰 𝐬𝐜𝐞𝐧𝐚𝐫𝐢𝐨:
1) Suppose a process is about to return to user mode after executing a system call, and it finds that it has no outstanding signals.
2) Immediately after checking, the kernel handles an interrupt and sends the process a signal. (For instance, a user hits the “break” key.)
3) What does the process do when the kernel returns from the interrupt?
_______________________________________________________________________________
𝐄𝐱𝐩𝐥𝐚𝐧𝐚𝐭𝐢𝐨𝐧:
The key part is in the exit_to_user_mode_loop() function:
– The kernel explicitly checks for _TIF_SIGPENDING (pending signals)
– This check is part of a loop that continues processing until all work is done
– Each iteration enables interrupts while handling work (to allow new signals to arrive)
– Then it disables interrupts and rechecks the flags
– This loop structure ensures that even signals that arrive at the last moment get handled
This design effectively prevents the race condition , where a signal arrives just after checking but before returning to user mode. The kernel will see any such signals during the final check with interrupts disabled.
The complete flow through.
syscall_exit_to_user_mode()
→ exit_to_user_mode_prepare()
→ exit_to_user_mode_loop()
For more details check – kernel/entry/common.c
__________________________________________________________________
𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐎𝐩𝐩𝐨𝐫𝐭𝐮𝐧𝐢𝐭𝐢𝐞𝐬:
A) 𝐒𝐞𝐥𝐟-𝐏𝐚𝐜𝐞𝐝 𝐂𝐨𝐮𝐫𝐬𝐞:
Learn at your own pace
Structured kernel programming modules
Practical examples, bug study
Hands-on debugging experience
B) 𝐂𝐥𝐚𝐬𝐬𝐫𝐨𝐨𝐦 𝐓𝐫𝐚𝐢𝐧𝐢𝐧𝐠 𝐟𝐨𝐫 𝐅𝐫𝐞𝐬𝐡𝐞𝐫𝐬:
5 Months intensive program
Placement support
Real-world bug analysis
Kernel development fundamentals
Live projects & case studies
C) 𝐖𝐞𝐞𝐤𝐞𝐧𝐝 𝐎𝐧𝐥𝐢𝐧𝐞 𝐂𝐨𝐮𝐫𝐬𝐞 𝐟𝐨𝐫 𝐖𝐨𝐫𝐤𝐢𝐧𝐠 𝐏𝐫𝐨𝐟𝐞𝐬𝐬𝐢𝐨𝐧𝐚𝐥𝐬:
180+ Hours of training
8 Months comprehensive program
Flexible for working professionals
📽 𝐘𝐨𝐮𝐓𝐮𝐛𝐞 𝐜𝐡𝐚𝐧𝐧𝐞𝐥
https://lnkd.in/eYyNEqp
𝐌𝐨𝐝𝐮𝐥𝐞𝐬 𝐂𝐨𝐯𝐞𝐫𝐞𝐝 –
1) System Programming
2) Linux kernel internals
3) Linux device driver
4) Linux socket programming
5) Linux network device driver, PCI, USB driver code walk through, Linux
crash analysis and Kdump
7) JTag debugging
– 𝐏𝐫𝐢𝐜𝐢𝐧𝐠 :
https://lnkd.in/ePEK2pJh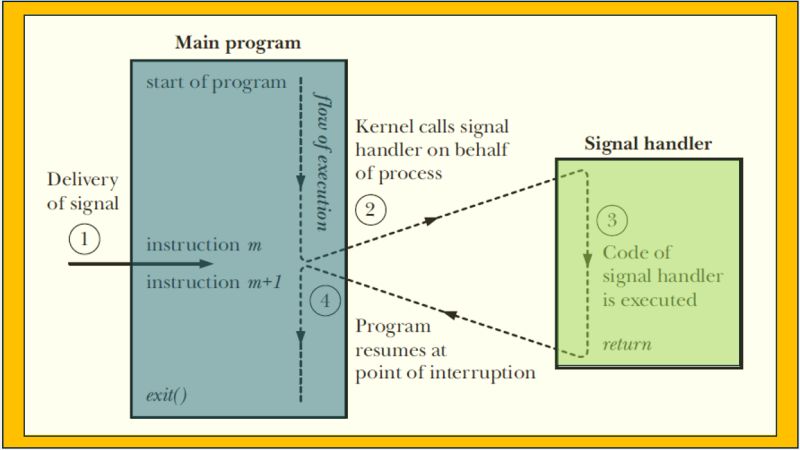
container_of` macro allows you to find the parent structure from a pointer to one of its members. One of the most ingenious pieces of C programming in the Linux kernel.
Here’s the definition:
hashtag#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member) *__mptr = (ptr); \
(type *)((char *)__mptr – offsetof(type, member)); })
Let’s break down:
1. Takes a pointer to a member (`ptr`)
2. The type of the container structure (`type`)
3. The name of the member within the structure (`member`)
4. Returns a pointer to the container structure
The most interesting part of the macro is:
const typeof(((type *)0)->member) *__mptr = (ptr);
Fascinating trick using a null pointer cast. Let’s analyze why this works:
– `(type *)0` casts the value 0 (NULL) to a pointer of type `type*`
– `((type *)0)->member` accesses the `member` field of this null pointer
– This doesn’t actually dereference memory (which would cause a crash), but instead lets the compiler determine the type of `member`
– `typeof()` extracts this type information
– `__mptr` is then declared as a pointer to this type and assigned the value of `ptr`
Why is This Implementation Valuable?
1. Enables C Object-Oriented Patterns
Consider this example:
struct device {
int id; // Offset 0
char name[8]; // Offset 4
struct list_head list; // Offset 12
};
When a function receives a `list_head` pointer, it can find the containing `device` structure:
void some_list_function(struct list_head *list_ptr) {
struct device *dev;
dev = container_of(list_ptr, struct device, list);
printf(“Device ID: %d\n”, dev->id);
printf(“Device Name: %s\n”, dev->name);
}
2. Type Safety
The use of `typeof` ensures that `ptr` is of the correct type expected for the member. This provides compile-time type checking.
3. Zero Runtime Overhead
The entire macro resolves to simple pointer arithmetic. There’s no function call overhead, dynamic type checking, or any other runtime cost.
4. Maintains Encapsulation
Exposes only the necessary structures while keeping their containing structures private, enhancing modularity.
Understanding the Null Pointer Cast
The line `const typeof( ((𝐭𝐲𝐩𝐞 *)0)->member) *__mptr = (ptr);` often confuses developers new to kernel code. The null pointer (0) is specifically chosen because it’s a safe way to access type information without risking memory access.
Practical Applications
The `container_of` macro is used extensively throughout the kernel:
1. 𝐃𝐞𝐯𝐢𝐜𝐞 𝐃𝐫𝐢𝐯𝐞𝐫 𝐌𝐨𝐝𝐞𝐥: Finding device structures from their embedded kobjects
2. 𝐋𝐢𝐧𝐤𝐞𝐝 𝐋𝐢𝐬𝐭𝐬: Retrieving the containing structure from a list entry
3. 𝐑𝐂𝐔: Accessing container structures in lock-free code
4. 𝐒𝐮𝐛𝐬𝐲𝐬𝐭𝐞𝐦 𝐈𝐧𝐭𝐞𝐫𝐟𝐚𝐜𝐞𝐬: Extending core functionality through composition


Two embedded engineers with identical experience sit in the same interview. Both have 2-3 years experience (applicable for freshers also), strong Linux/C skills, solid DSA knowledge.
𝐈𝐧𝐭𝐞𝐫𝐯𝐢𝐞𝐰 𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧: “𝐇𝐨𝐰 𝐝𝐨 𝐲𝐨𝐮 𝐯𝐚𝐥𝐢𝐝𝐚𝐭𝐞 𝐞𝐦𝐛𝐞𝐝𝐝𝐞𝐝 𝐟𝐢𝐫𝐦𝐰𝐚𝐫𝐞 𝐪𝐮𝐚𝐥𝐢𝐭𝐲?”
❌ Candidate A: “I do thorough testing and code reviews.”
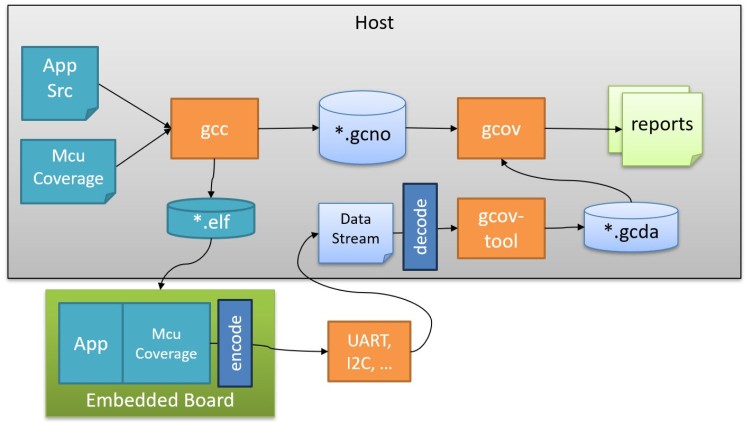
✔️ Candidate B: “I use GCOV for coverage analysis. gcc –coverage revealed
untested error paths in our SPI driver that could have caused field failures. I target 80%+ coverage for production code.”
Result: Candidate B gets the offer.
𝐖𝐡𝐲 𝐓𝐨𝐨𝐥 𝐊𝐧𝐨𝐰𝐥𝐞𝐝𝐠𝐞 𝐖𝐢𝐧𝐬
𝐓𝐨𝐨𝐥-𝐒𝐚𝐯𝐯𝐲 𝐑𝐞𝐬𝐩𝐨𝐧𝐬𝐞 𝐬𝐢𝐠𝐧𝐚𝐥𝐬:
✅ Production quality experience
✅ Industry-standard practices
✅ Systematic development approach
✅ Can prevent costly field failures
𝐓𝐡𝐞 𝐄𝐚𝐬𝐲 𝐖𝐢𝐧
Complex Skills: 6+ months each (kernel internals, advanced DSA) Professional Tools: 2-3 weeks to master ⚡
Impact: Same resume + tool knowledge = 15-25% higher salary
𝐘𝐨𝐮𝐫 𝐀𝐝𝐯𝐚𝐧𝐭𝐚𝐠𝐞 𝐏𝐥𝐚𝐧
# Learn GCOV basics (1 weekend): ->
gcc –coverage -o program source.c
gcov source.c
𝐂𝐥𝐢𝐜𝐤 𝐛𝐞𝐥𝐨𝐰 𝐟𝐨𝐫 𝐝𝐞𝐭𝐚𝐢𝐥𝐬 :
https://lnkd.in/g4T_RcMq
𝐓𝐚𝐛𝐥𝐞 𝐨𝐟 𝐂𝐨𝐧𝐭𝐞𝐧𝐭𝐬-
[What is GCOV?]
[Why Use GCOV?]
[When to Use GCOV?]
[Understanding GCOV Output]
[Expert vs Novice Analysis]
[Advanced Techniques]
[Industry Best Practices]
[Practical Implementation]
𝐋𝐞𝐚𝐫𝐧 𝐦𝐨𝐫𝐞 -> https://lnkd.in/g4T_RcMq
# Build portfolio examples
# Prepare tool-focused interview talking points
𝐁𝐨𝐭𝐭𝐨𝐦 𝐋𝐢𝐧𝐞
While others study algorithms for months, you can master professional tools in weeks and immediately stand out in interviews.
Tool knowledge shows professional maturity that hiring managers need.
📢 Coming Next:
More embedded development tools that create interview advantages—static analysis, debugging utilities, profiling tools. Follow for weekly insights!
A production server hang completely because of one “atomic” operation? Here’s a real Linux kernel bug that brought down enterprise systems worldwide – A Perfect case study for understanding multi-CPU concurrency challenges!
The Linux block layer had this code in the blk-mq (multi-queue block I/O) subsystem:
// 𝐂𝐨𝐮𝐧𝐭 𝐧𝐞𝐬𝐭𝐞𝐝 𝐟𝐫𝐞𝐞𝐳𝐞 𝐨𝐩𝐞𝐫𝐚𝐭𝐢𝐨𝐧𝐬
freeze_depth = atomic_inc_return(&q->mq_freeze_depth);
if (freeze_depth == 1) {
percpu_ref_kill(&q->q_usage_counter); // Stop I/O
}
𝐖𝐡𝐚𝐭 𝐜𝐨𝐮𝐥𝐝 𝐠𝐨 𝐰𝐫𝐨𝐧𝐠?
This bug affected ALL multi-core systems running Linux 4.19+ with blk-mq enabled, including:
Intel Xeon servers with NVMe storage
AMD EPYC systems with SATA SSDs in RAID
ARM64 servers with shared storage controllers
Enterprise systems with multipath storage configurations
what happened when two CPUs tried to freeze the same I/O queue is shown in images attached.
The solution was elegantly simple but required mainline kernel changes:
// 𝐁𝐄𝐅𝐎𝐑𝐄: 𝐑𝐚𝐜𝐞-𝐩𝐫𝐨𝐧𝐞 𝐚𝐭𝐨𝐦𝐢𝐜 𝐨𝐩𝐞𝐫𝐚𝐭𝐢𝐨𝐧𝐬
freeze_depth = atomic_inc_return(&q->mq_freeze_depth);
if (freeze_depth == 1) percpu_ref_kill();
// AFTER: Mutex-protected critical section
mutex_lock(&q->mq_freeze_lock);
if (++q->mq_freeze_depth == 1) {
percpu_ref_kill(&q->q_usage_counter);
}
mutex_unlock(&q->mq_freeze_lock);
𝐓𝐡𝐢𝐬 𝐫𝐚𝐜𝐞 𝐜𝐨𝐧𝐝𝐢𝐭𝐢𝐨𝐧 𝐜𝐚𝐮𝐬𝐞𝐝 𝐰𝐢𝐝𝐞𝐬𝐩𝐫𝐞𝐚𝐝 𝐩𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐟𝐚𝐢𝐥𝐮𝐫𝐞𝐬:
RAID arrays stuck in recovery
Journal threads unable to commit
Applications frozen during file writes
System requiring reboot
Key Lessons for System Design
1. Per-CPU Data Isn’t Always the Answer
2. Atomic Operations Have Limits
3. Critical Sections Must Be Identified
Questions for Discussion
1) How do you handle race conditions in your multi-threaded applications?
2) What debugging tools do you use for concurrency issues?
3) Have you encountered similar production issues with “atomic” operations?
🎓 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐎𝐩𝐩𝐨𝐫𝐭𝐮𝐧𝐢𝐭𝐢𝐞𝐬:
A) 𝐒𝐞𝐥𝐟-𝐏𝐚𝐜𝐞𝐝 𝐂𝐨𝐮𝐫𝐬𝐞:
𝐏𝐥𝐚𝐜𝐞𝐦𝐞𝐧𝐭 𝐬𝐮𝐩𝐩𝐨𝐫𝐭
Learn at your own pace
Structured kernel programming modules
Practical examples, bug studies like this one
Hands-on debugging experience
B) 𝐖𝐞𝐞𝐤𝐞𝐧𝐝 𝐎𝐧𝐥𝐢𝐧𝐞 𝐂𝐨𝐮𝐫𝐬𝐞 𝐟𝐨𝐫 𝐖𝐨𝐫𝐤𝐢𝐧𝐠 𝐏𝐫𝐨𝐟𝐞𝐬𝐬𝐢𝐨𝐧𝐚𝐥𝐬:
180+ Hours of comprehensive training
8 Months structured program
Flexible scheduling for working professionals
𝐌𝐨𝐝𝐮𝐥𝐞𝐬 𝐂𝐨𝐯𝐞𝐫𝐞𝐝:
System Programming
Linux kernel internals
Linux device driver development
Linux socket programming
Network device drivers, PCI, USB driver walkthrough
Linux crash analysis and Kdump
JTAG debugging

Ftrace is a powerful tracing utility built directly into the Linux kernel that allows developers to trace kernel function calls with minimal overhead. It lives in the kernel’s debugfs, typically mounted at
/𝐬𝐲𝐬/𝐤𝐞𝐫𝐧𝐞𝐥/𝐝𝐞𝐛𝐮𝐠/𝐭𝐫𝐚𝐜𝐢𝐧𝐠/
𝐒𝐞𝐭𝐭𝐢𝐧𝐠 𝐔𝐩 𝐅𝐭𝐫𝐚𝐜𝐞
The provided example shows how to configure Ftrace:
mount -t debugfs nodev /sys/kernel/debug
cd /sys/kernel/debug/tracing
# Set function graph tracer
echo function_graph > current_tracer
# Filter for specific functions
echo ‘__x64_sys_brk’ >> set_ftrace_filter
echo ‘do_brk_flags’ >> set_ftrace_filter
echo ‘__x64_sys_mmap’ >> set_ftrace_filter
echo ‘__x64_sys_mmap_pgoff’ >> set_ftrace_filter
echo ‘do_mmap’ >> set_ftrace_filter
echo ‘vm_mmap’ >> set_ftrace_filter
echo ‘vm_mmap_pgoff’ >> set_ftrace_filter
echo ‘get_unmapped_area’ >> set_ftrace_filter
echo ‘vm_unmapped_area’ >> set_ftrace_filter
# Enable tracing
echo 1 > tracing_on
𝐅𝐭𝐫𝐚𝐜𝐞 𝐢𝐧 𝐀𝐜𝐭𝐢𝐨𝐧: 𝐌𝐞𝐦𝐨𝐫𝐲 𝐌𝐚𝐧𝐚𝐠𝐞𝐦𝐞𝐧𝐭 𝐄𝐱𝐚𝐦𝐩𝐥𝐞
Let’s analyze the output from a memory test program calling brk, mmap etc:
— Testing brk() syscall —
Initial program break: 0x425000
Program break increased by 1MB: 0x525000
Successfully wrote to the allocated memory
Program break restored: 0x425000
— Testing mmap() syscall —
Anonymous mapping at: 0x7f95fc9f2000
Wrote to anonymous mapping: Testing anonymous mapping
Anonymous mapping unmapped
File mapping at: 0x7f95fc9f2000
First 20 bytes of /etc/passwd: root:x:0:0:root:/roo
File mapping unmapped
Fixed mapping at requested address 0x600000000000
Map with – linux/v6.14.5/source/mm/mmap.c
𝐅𝐭𝐫𝐚𝐜𝐞 𝐫𝐞𝐯𝐞𝐚𝐥𝐬 𝐭𝐡𝐞 𝐞𝐱𝐞𝐜𝐮𝐭𝐢𝐨𝐧 𝐩𝐚𝐭𝐡 𝐰𝐢𝐭𝐡 𝐭𝐢𝐦𝐢𝐧𝐠 𝐝𝐞𝐭𝐚𝐢𝐥𝐬:
4) __x64_sys_mmap() {
4) vm_mmap_pgoff() {
4) do_mmap() {
4) get_unmapped_area() {
4) vm_unmapped_area();
4) }
4) }
4) }
4) }
𝐏𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞 𝐢𝐧𝐬𝐢𝐠𝐡𝐭𝐬:
14) __x64_sys_mmap() {
14) 4.440 us | do_mmap();
14) 4.881 us | }
𝐅𝐨𝐫 𝐟𝐢𝐱𝐞𝐝 𝐦𝐚𝐩𝐩𝐢𝐧𝐠𝐬:
6) __x64_sys_mmap() {
6) 1.794 us | do_mmap();
6) ! 409.690 us | } <— exclamation mark indicates a long execution time
𝐁𝐞𝐧𝐞𝐟𝐢𝐭𝐬 𝐟𝐨𝐫 𝐃𝐞𝐛𝐮𝐠𝐠𝐢𝐧𝐠
– Function call hierarchy: Seeing what functions are called in what order
– Performance measurement: Precise timing of each function
– Bottleneck identification: Finding unexpectedly slow operations
– System understanding: Revealing implementation details of system calls
𝐋𝐢𝐦𝐢𝐭𝐚𝐭𝐢𝐨𝐧𝐬 𝐚𝐧𝐝 𝐂𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞𝐬
– Kernel-only visibility: Limited to kernel space, doesn’t show userspace activities
– Buffer constraints: Trace buffers can overflow during extended tracing
– Security implications: May expose sensitive kernel information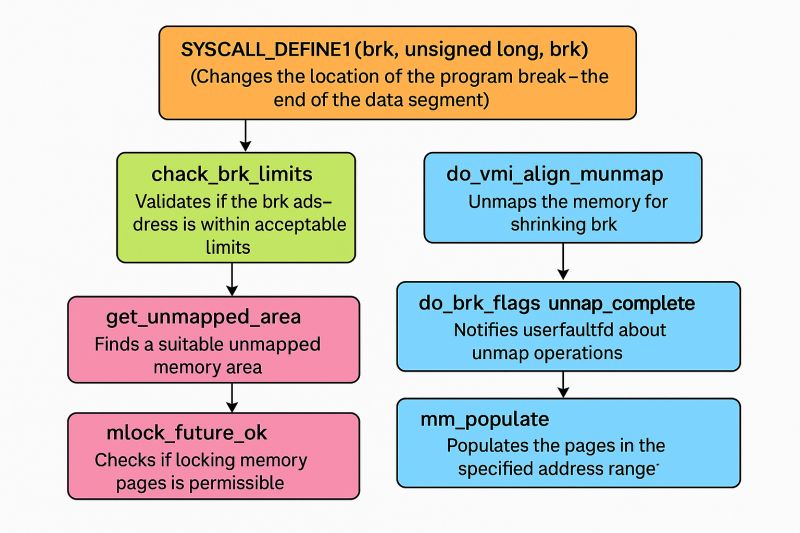
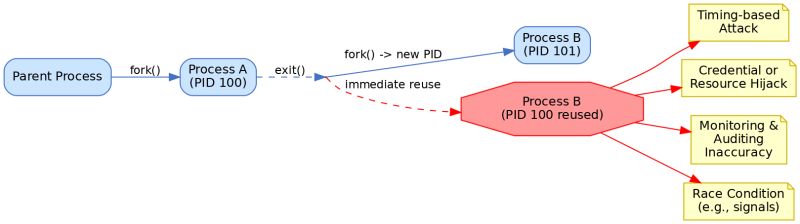
Linux does not immediately recycle process identifiers (PIDs) for new processes after a process exits. Instead, PIDs are allocated sequentially up to a maximum and only reused after the range wraps around.
𝐊𝐞𝐲 𝐑𝐞𝐚𝐬𝐨𝐧𝐬 𝐟𝐨𝐫 𝐀𝐯𝐨𝐢𝐝𝐢𝐧𝐠 𝐈𝐦𝐦𝐞𝐝𝐢𝐚𝐭𝐞 𝐏𝐈𝐃 𝐑𝐞𝐮𝐬𝐞:
𝐓𝐡𝐰𝐚𝐫𝐭𝐢𝐧𝐠 𝐓𝐢𝐦𝐢𝐧𝐠-𝐁𝐚𝐬𝐞𝐝 𝐀𝐭𝐭𝐚𝐜𝐤𝐬:
Prevents attackers from predicting when a PID will be free and immediately acquiring it. This blocks attackers from spawning malicious processes with the same PID as just-terminated privileged processes.
𝐏𝐫𝐞𝐯𝐞𝐧𝐭𝐢𝐧𝐠 𝐂𝐫𝐞𝐝𝐞𝐧𝐭𝐢𝐚𝐥/𝐑𝐞𝐬𝐨𝐮𝐫𝐜𝐞 𝐇𝐢𝐣𝐚𝐜𝐤𝐢𝐧𝐠:
Blocks impersonation attacks where a new process might inherit security tokens or permissions from a recently terminated process with the same PID.
𝐌𝐚𝐢𝐧𝐭𝐚𝐢𝐧𝐢𝐧𝐠 𝐀𝐜𝐜𝐮𝐫𝐚𝐭𝐞 𝐌𝐨𝐧𝐢𝐭𝐨𝐫𝐢𝐧𝐠 & 𝐀𝐮𝐝𝐢𝐭𝐢𝐧𝐠:
Ensures that system monitors, loggers, and auditing tools can accurately track processes without confusion. At any given moment, each PID refers to only one specific process.
𝐀𝐯𝐨𝐢𝐝𝐢𝐧𝐠 𝐑𝐚𝐜𝐞 𝐂𝐨𝐧𝐝𝐢𝐭𝐢𝐨𝐧𝐬:
Eliminates dangerous race conditions where system operations (signals, /proc access, etc.) might accidentally target a new process that inherited a PID instead of the intended original process.
𝐂𝐡𝐞𝐜𝐤 𝐝𝐞𝐬𝐢𝐠𝐧 𝐜𝐡𝐚𝐧𝐠𝐞𝐬-
linux.git/commit/?id=5fdee8c4a5e1800489ce61963208f8cc55e42ea1
linux/v4.14.336/source/kernel/pid.c
linux/v6.15-rc4/source/kernel/pid.c
1) 𝐂𝐨𝐫𝐞 𝐀𝐥𝐥𝐨𝐜𝐚𝐭𝐢𝐨𝐧 𝐌𝐞𝐜𝐡𝐚𝐧𝐢𝐬𝐦
nr = idr_alloc_cyclic(&tmp->idr, NULL, pid_min, pid_max, GFP_ATOMIC);
2) 𝐏𝐈𝐃 𝐑𝐚𝐧𝐠𝐞 𝐌𝐚𝐧𝐚𝐠𝐞𝐦𝐞𝐧𝐭
// Determine minimum PID value for allocation
int pid_min =1;
if(idr_get_cursor(&tmp->idr)> RESERVED_PIDS)
pid_min = RESERVED_PIDS;
3) 𝐋𝐚𝐫𝐠𝐞 𝐏𝐈𝐃 𝐒𝐩𝐚𝐜𝐞 𝐂𝐨𝐧𝐟𝐢𝐠𝐮𝐫𝐚𝐭𝐢𝐨𝐧
init_pid_ns.pid_max =min(pid_max_max,max_t(int, init_pid_ns.pid_max, PIDS_PER_CPU_DEFAULT *num_possible_cpus()));
pid_max_min =max_t(int, pid_max_min, PIDS_PER_CPU_MIN *num_possible_cpus());
4) 𝐍𝐚𝐦𝐞𝐬𝐩𝐚𝐜𝐞 𝐈𝐬𝐨𝐥𝐚𝐭𝐢𝐨𝐧
struct pid_namespace init_pid_ns = {
.ns.count =REFCOUNT_INIT(2),
.idr =IDR_INIT(init_pid_ns.idr),
// …
};
𝐓𝐡𝐞 𝐬𝐲𝐬𝐭𝐞𝐦 𝐩𝐫𝐞𝐯𝐞𝐧𝐭𝐬 𝐢𝐦𝐦𝐞𝐝𝐢𝐚𝐭𝐞 𝐏𝐈𝐃 𝐫𝐞𝐮𝐬𝐞 𝐛𝐲:
– Using cursor-based sequential, cyclic PID allocation
– Maintaining a large PID space.
– Ensuring PIDs are not reused until the entire PID space is exhausted
– Providing namespace isolation for container environments
𝐒𝐨𝐮𝐫𝐜𝐞𝐬:
Stack Overflow – Linux PID recycling behavior
GitHub Issue – Kernel avoids quick PID reassignments to prevent issues
Exploit-DB (Polkit) – Timing attack & auth hijack via PID reuse
Security StackExchange – PID uniquely identifies an active process
Superuser – Quick PID reuse seen as a security hazard
struct generic_struct {
int id;
float value;
char name[20];
int m;
};
hashtag#define GENERIC_STRUCT_STAT(m) sizeof(((struct generic_struct *)0)->m)
int main() {
int x = GENERIC_STRUCT_STAT(m); <———-
return0;
}
𝐖𝐡𝐚𝐭 𝐰𝐢𝐥𝐥 𝐡𝐚𝐩𝐩𝐞𝐧 𝐰𝐡𝐞𝐧 𝐭𝐡𝐞 𝐦𝐚𝐜𝐫𝐨 𝐆𝐄𝐍𝐄𝐑𝐈𝐂_𝐒𝐓𝐑𝐔𝐂𝐓_𝐒𝐓𝐀𝐓(𝐦) 𝐢𝐬 𝐮𝐬𝐞𝐝?
______________________________________________________________
A) The program will crash due to dereferencing a null pointer.
B) Compilation error.
C) The size of the member m (int) will be calculated, which is typically 4 bytes on most systems.
D) The size of the entire structure generic_struct will be calculated.